Domain
AWS Infrastructure as Code and Continuous Deployment (Iac)
Objective: Within an AWS environment compare Cloud Formation Templates (CFT), Terraform (TF) and Ansible (Ans).
Why: See which IaC Continuous Deployment Stack, is easier to use, the fastest.
AWS Region: London
What: The solution is simple and is a standard pattern which anyone can replicate (using CFT for eg):
- VPC with an internet gateway
- 3 public subnets and 3 private subnets
- 3 AZs
- Private subnet (db) are connected to the public subnets via a NAT
- Elastic IP’s or EIPs are used for the NAT
- Routing tables and security groups are created to allow traffic to go from and to the EC2’s.
- EC2’s are t2.micro free-tier (AWS Linux AMIs)
- Each EC2 has an Apache HTTd (daemon) Web Server
- Web Server has a Php index.html file with a simple message
- The EC2 instances and Web Servers are deployed using Auto-Scaling with 3 nodes
- There are 2 LBs (load balancers) – one for public and one for the private subnets
- The CFT, TF, Ans scripts will output the DNS name of the public load balancer
Sequence:
- EC2’s in the private network are deployed first
- The VM’s in the public network will give a message (“Foreground website”) and then curl to the internal load balancer to get the text of the EC2’s in the private network (“Background info”) after that.
- Because the index.html is a static file which is created at the deployment of the EC2’s, the scripts must deploy the EC2’s in the private network first.
Security:
- When deploying the scripts first create a key within EC2 to be able to ssh to the EC2’s.
- Security Group that is used in public subnets allows all connections from a test PC (the IP-address of this/or your PC which is passed as a parameter), and web traffic from all IP-addresses.
YAML and JSON: CFT supports both, TF and Ans have limitations with YAML, though I prefer YAML, JSON was used.
Tear down the stacks after deployment and testing.
CloudFormation
The order in which resources are deployed is determined by CloudFormation. There are dependencies (see order above) and often there are errors if people deploy this manually, or the configuration of the dependencies is incorrect.
There are some caveats: the order in which objects are deployed can be different when the template is deployed multiple times (for instance creating a base CFT and then changing input or output parameters to deploy a 2nd stack). Sometimes the order is not logical: when one deploys both network components like route tables and NAT gateways, it is not wise to deploy autoscaling groups at the same time (where Virtual Machines depend on the network for their initialization scripts).
The dependency can be set in the template, by using the “DependsOn” keyword. This keyword uses the names as they are provided by the developer of the template:
“AutoScalingGroupPrivate”: {
“Type”: “AWS::AutoScaling::AutoScalingGroup”,
“DependsOn”: [“SecurityGroupPublic”, “PublicSubnetRouteTable”,
“SecurityGroupPrivate”, “PrivateGatewayRouteAZ1”,
“PrivateGatewayRouteAZ2”, “PrivateGatewayRouteAZ3”],
Within CFT you cannot create objects in a loop: though the configuration for all private subnets are very much alike, there are three different objects in the CloudFormation file:
“PrivateSubnetRouteTableAZ2”: {
“Type”: “AWS::EC2::RouteTable”,
“Properties”: {
“Tags” : [ {
“Key”: “Name”,
“Value”: {“Fn::Join”: [“”,
[{“Ref”: “Name”}, “-private-subnet-routetable-AZ2”]]}
}],
“VpcId”: {“Ref”: “VPC”}
}
}
The Join-function of CloudFormation is used to connect the contents of the variable Name with the static text “-private-subnet-routetable-AZ2”. AWS provides some work-arounds if you need to determine an AMI-id dynamically.
Advantages, Disadvantages of CFT
CFT is an integral part of AWS, and if we were to deploy TF or Ans in AWS, we are using the API of AWS (not the native service). This allows an easy deletion of all resources within a CFT stack or template. This can be a disadvantage as well given that we cannot enhance the CFT. This is probably not a big issue, since CFT is tightly integrated with AWS services and provides most of what you will need. However, it is noted that for some reason CFT is slower than TF though faster than Ans.
Terraform
TF has its own languages for its templates, which looks somewhat like JSON. You can federate a configuration, using different files for different parts and TF will join the files together in the right subdirectory to fulfil a deployment. Sensitive information like Keys should be stored in another directory.
TF deployments have 3 stages: 1) init (bootstrap, runtime, download modules to the directory) 2) plan (TF looks at differences in the config files and the environment platform of deployment and 3) output and apply.
Typical commands which were used are:
terraform init –var-file=/home/user/terraform.tfvars
terraform plan –var-file=/home/user/terraform.tfvars -out terraform.tfplans
terraform apply terraform.tfplans
terraform destroy –var-file=/home/user/terraform.tfvars
It is possible to change variables on the command line, these take precedence above the variables in the configuration files. Like a CFT, TF will determine the order in which objects are deployed, using a ‘depends on’ exists condition (similar to CFT). In TF the object names are combined with the name of the class to an object, which was created previously.
resource “aws_autoscaling_group” “autoscaling_group_private” {
name = “${var.name}-asg-group-private”
[…]
depends_on = [“aws_security_group.security_group_public”,
“aws_route_table.public_subnet_route_table”,
“aws_security_group.security_group_private”,
“aws_route_table_association.subnet_private_route_table_association”,
“aws_internet_gateway.igw”]
}
In TF it is possible to loop through parts of the configuration. An example would be the 3 public subnets connecting to 1 route table:
resource “aws_route_table_association” “subnet_public_route_table_association” {
count = “${length(data.aws_availability_zones.available.names)}”
subnet_id = “${element(aws_subnet.publicsubnet.*.id,count.index)}”
route_table_id = “${aws_route_table.public_subnet_route_table.id}”
}
The above script indicates that the configuration will be executed 3 times (one per AZ). The count.index will increment from 0 – 2, for three availability zones. The element function will give back the individual route table associations, each one will take a public subnet and connect it to the (one) public route table.
You can use external data with TF to create resources. An example is to get the most recent AMI number for AWS Linux.
data “aws_ami” “aws_linux” {
most_recent = true
owners = [“amazon”]
filter {
name = “name”
values = [“amzn-ami-hvm-20*”]
}
filter {
name = “architecture”
values = [“x86_64”]
}
filter {
name = “virtualization-type”
values = [“hvm”]
}
filter {
name = “root-device-type”
values = [“ebs”]
}
}
TF also provides a ‘state lock’. This is clever. Every time you use the TF plan stage (apply, destroy), a hidden file (.terraform.tfstate.lock.info) is created which contains the name of the user that started the command and the date and time of the current run. When another operator tries to use one of the change commands, TF generates an error.
TF can destroy objects that have been made by earlier TF plans and TF ‘applies’, using TF ‘destroy’. This command uses the terraform.tfstate (JSON-)file with data (f.e. id’s, names of availability zones, etc). When you delete the whole directory without doing a terraform destroy first, you will have to delete everything that has been created in earlier stages by hand (AWS has similar features and steps when destroying a stack if you do it manually).
TF has modules (or a Library) written by its community that you can use. An example is the vpc-module, which will create routes, gateways, subnets etc. where just a few, relevant, parameters are given.
variable “azs” {
default = [“eu-west-1a”, “eu-west-1b”, “eu-west-1c”]
}
[…]
# NETWORKING #
module “vpc” {
source = “terraform-aws-modules/vpc/aws”
name = “${var.name}-VPC”
cidr = “${var.cidr_block}”
azs = “${var.azs}”
public_subnets = [“${cidrsubnet(var.cidr_block, 8, 1)}”,
“${cidrsubnet(var.cidr_block, 8, 2)}”,
“${cidrsubnet(var.cidr_block, 8, 3)}”]
private_subnets = [“${cidrsubnet(var.cidr_block, 8, 4)}”,
“${cidrsubnet(var.cidr_block, 8, 5)}”,
“${cidrsubnet(var.cidr_block, 8, 6)}”]
enable_nat_gateway = true
single_nat_gateway = false
create_database_subnet_group = false
enable_dns_hostnames = true
enable_dns_support = true
}
Advantages, Disadvantages of TF
Easy API integration with AWS services. Library, community of modules which are useful for reuse, ease of deployment. Fast deployment times. Platform independent which is useful if you want to reuse your scripts outside of AWS.
TF’s language is similar to JSON, it would be better if TF supported both YAML and JSON natively. The tag option is also missing in some objects which a big disadvantage when you have multiple deployments in the same VPC.
Ansible
To allow the Ans script to execute, an extra Python library is needed, installed by pip. For a VPC on AWS we need boto, boto3 and botocore. For the ipaddr function, we need the netaddr Python package: sudo pip install boto boto3 botocore netaddr
For some reason Ans does not provide a local file with IDs which are used in previous deployments. This is a major weakness when compared to TF. This means that the ANS deployments do not see if previously created objects are in or outside of Ans.
For example, Elastic IP Addresses: restart the Ans playbook, which will create an extra instead of reusing the previous assigned IP-addresses. This is an issue since the EIPs are used for the NAT gateway. This means that Ans does not recognise existing NAT gateways.
Ans also does not wait for the stack creation to end, when configuring the NAT. If other objects rely on the NAT this creates problems (eg. EC2 instances in the private subnet). To start up an EC2 instance you need ‘userdata’ and a parameter within user data will be the NAT. The user data is a part of the start-up script, and for instance, I will need to download Apache from the internet. For Ans given the above issue you will need to change the time-out parameters to 10 minutes to deploy the stack.
Advantages, Disadvantages of Ansible
Platform independent, supports JSON, fairly intuitive, easy API integration with AWS. There are modules (libraries) which can be used within AWS (as with TF and github repo), but these are not as easy to use or understand like TF.
As with TF the tag option is missing in some which will create management and cost confusion when you have multiple deployments in the same VPC.
There are also some minor bugs. Example, when the user_data of a launch configuration is changed, one would expect the launch configuration to be updated or to be deleted/recreated. This isn’t done in Ansible: you have to delete the launch configuration by hand (or by another playbook) to let Ansible recreate it.
There is no default way to “destroy” or “rollback”: you must create a new playbook to implement the deletion of objects. This is not straightforward and takes time to figure out.
For example: information about the VPC is sometimes needed to be able to destroy an object. To make this possible, there are special facts objects within the AWS module to get information about objects that are present.
name: Get VPC facts
ec2_vpc_net_facts:
region: “{{region}}”
filters:
“tag:Name”: “{{nameprefix}}-VPC”
register: vpc
The Elastic IP Addresses (EIP’s) are also a problem in the deletion: Ans doesn’t store information about automatic creation (or not) of EIP’s. At deletion, the EIP’s will not be deleted. This will cause problems because each time you rollout new NAT Gateways, new EIP’s will be used. The old EIP’s will never be reused. Though this can be solved by deleting ALL existing EIP’s in the VPC, this can cause problems when you have multiple playbooks that use the same VPC.
The performance of Ansible is very slow: the duration of the create script is about twice as long as the creation with CloudFormation: more than 10 minutes.
Conclusion
On average for 5 deployments:
CF = CloudFormation, TF = Terraform, Ans = Ansible, CLI = Command Line Interface
| CF via web console | CF via the AWS CLI | TF, not using extra modules | TF, using extra modules | Ans, not using extra modules | Ans, using extra modules |
| 5:25 | 5:04 | 4:11 | 4:05 | 10:19 | n/a |
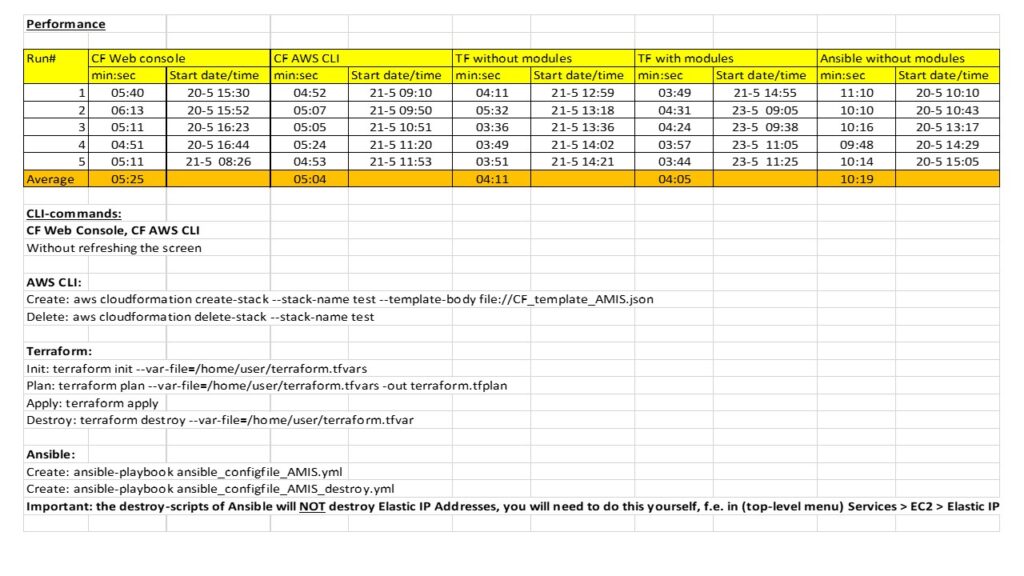
TF was the quickest, which is somewhat surprising given CFT are native services. TF also has more options than CFT indicating a maturity gap. Ans was by far the slowest, and most cumbersome to use. TF and CFT deploy multiple objects at once. Ans does not. Both TF and CFT store IDs locally. Ans does not which is a major issue when deploying objects that do not have labels (EIPs). Ans does not see the difference between the playbook and the current platform. Both CFT and TF do. This makes CFT, TF much better for IaC.
Bottom Line: If you are staying within AWS and do not plan on reusing the IaC process on other platforms use CFT due to its YAML-JSON support, ease of use and service integration. If you want to reuse the scripts and deployment templates across platforms or need more options to customise the deployments of stacks, use TF.
==END