AWS S3-based Data Lakes and Snowflake are both powerful solutions for data storage and analysis, but they serve different use cases and operational needs. Below are the distinct use cases for each, helping to identify when one might be more appropriate than the other.
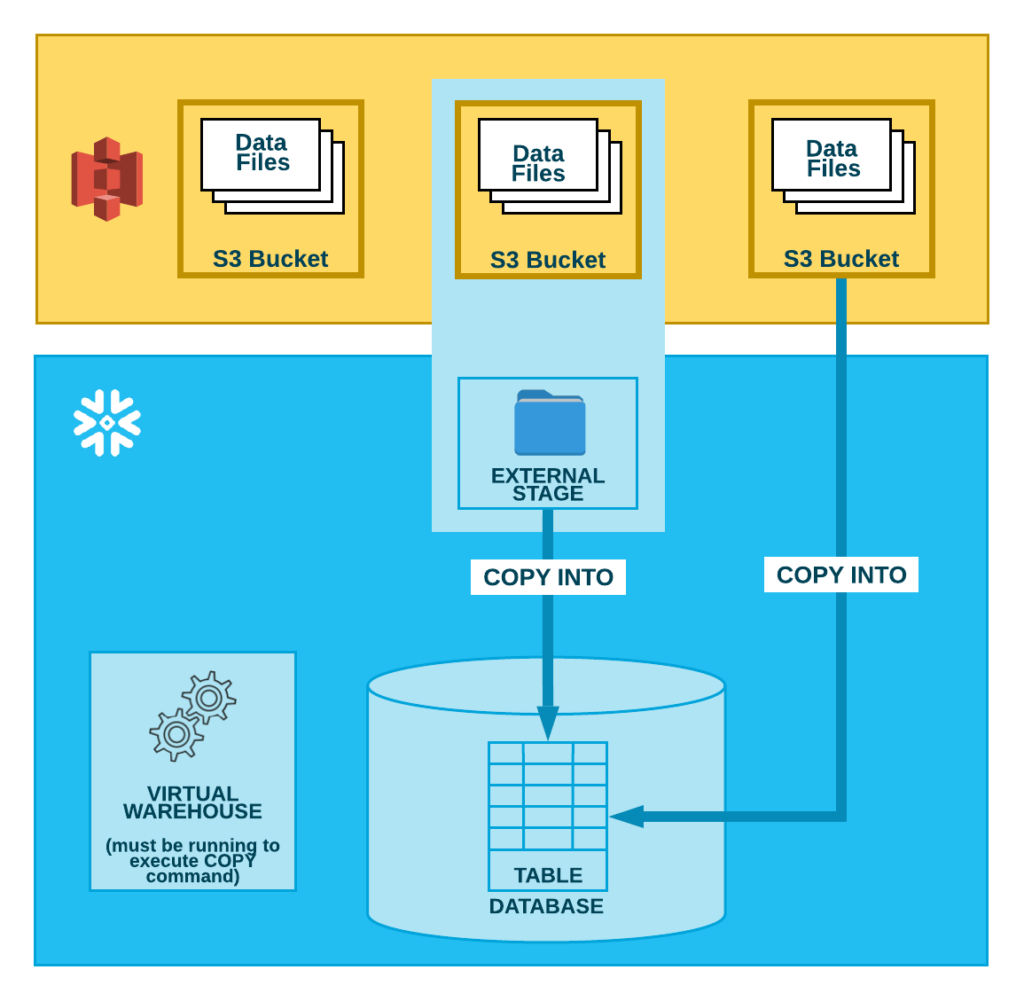
AWS S3 Data Lake
1. Large-scale Data Storage:
- Cost-effective Storage: S3 offers a highly cost-effective solution for storing massive volumes of data. It’s ideal for raw data that may not be accessed frequently but needs to be retained, such as logs, raw event data, or historical data.
- Data Lake Architectures: S3 is commonly used as the storage layer for a Data Lake architecture, where data can be kept in any format, scale easily, and be used for diverse analytical workloads including big data processing, machine learning, and real-time analytics.
2. High Durability and Availability:
- S3 provides 99.999999999% (11x 9’s) durability and stores data across multiple systems and facilities, making it extremely reliable for critical data backup and disaster recovery.
3. Integrated AWS Services:
- It integrates seamlessly with other AWS services like AWS Glue for data cataloging, AWS Athena for SQL querying directly in S3, and Amazon Redshift Spectrum for querying exabytes of unstructured data without moving it.
4. Flexibility in Data Processing:
- Users can choose from a vast ecosystem of data processing frameworks such as Apache Spark, Hadoop, and others that can read from and write to S3, providing flexibility in how data is processed.
Snowflake
1. Data Warehousing:
- Built-in SQL Capabilities: Snowflake is a fully managed data warehouse service designed for complex queries and high-speed analytics. It supports standard SQL for querying data, making it easy to use for those familiar with SQL.
- Performance Optimization: Features such as automatic clustering, scaling, and data sharding help in managing large datasets and query loads without manual tuning.
2. Concurrent Access and Scalability:
- Multi-Cluster Architecture: Allows multiple compute clusters to operate simultaneously without performance degradation, making it well-suited for enterprises with high concurrency requirements.
- Seamless Scaling: The ability to scale compute resources up or down automatically or on-demand based on the workload without impacting storage or ongoing operations.
3. Data Sharing and Secure Data Exchange:
- Data Sharing Capabilities: Snowflake provides features that allow companies to easily share governed and secure data in real-time with other Snowflake users. This is highly beneficial for organizations that need to share data across different departments or with external partners.
4. Built-in Business Intelligence and Security:
- Snowflake includes features for business intelligence, real-time analytics, and comprehensive security and governance, making it an all-in-one platform for data warehousing and analysis.
Choosing Between AWS S3 Data Lake and Snowflake
- Use AWS S3 Data Lake when you need a low-cost, scalable solution for storing vast amounts of raw, unstructured data that integrates well with a variety of AWS and open-source big data tools.
- Use Snowflake when you need a full-featured data warehousing solution with built-in capabilities for complex data processing, high concurrency, and real-time secure data sharing.
In practice, many businesses use both technologies in their data ecosystem, leveraging S3 for its expansive storage and Snowflake for its powerful data processing and analytics capabilities. This hybrid approach allows organizations to maximize their data’s value effectively.