Monolithic applications may need to be decomposed in service-oriented components, to run and scale in lightweight containers. Similarly, monolithic Data architectures may need to be rebuilt into service-oriented Data flows and processes. This can transform Data from being static and immutable, into being an asset contributing to new products and revenue streams. The following is based on an approach from JP Morgan found here.
Data Mesh Summary
- Organise Data around business domains, not IT silos, or technical roles
- Data should be domain-driven (the business language, context, purpose)
- Self-service platform to store, transfer, analyse data
- Data is viewed as a product not a static entity
- Data processes and analysis should not be ported to just one set of tools or platforms (some reasonable portability can be built in to the Data Mesh design)
Technology is clearly a domain-premised endeavour. Domain Driven Design is a key factor in the success of any large enterprise project. The business language and context are vital. A bank is not a telecom, which is not an e-tailer. Domain knowledge ensures that the very real constraints within that domain are understood within the project and its team. Most firms seek domain specific skills in their job advertisements. Using this approach, Data should also be organised around a domain.
There are 4 general principles when organising Data:
- The business domain should own the data end-to-end (not a technical team)
- A self-service platform is fundamental to a successful architectural approach where data is discoverable and shareable across an organization and ecosystem;
- Product thinking is central to the idea of a Data Mesh
- Data products must be built with governance and compliance that is automated and federated.
Data is obviously used within ITSM, SIEM and SIAM systems to enable humans to make better decisions or resolve problems, or lower operational costs. ‘Big Data’ systems use Machine Learning and Artificial intelligence to discover patterns and predict events or offer insights. These are important, but beyond the current use of data is the concept that data becomes a product and is monetised.
There is a Data Mesh community which offers some insights into Data as a product. An example from this network is JP Morgan.
Data Meshing at JPM
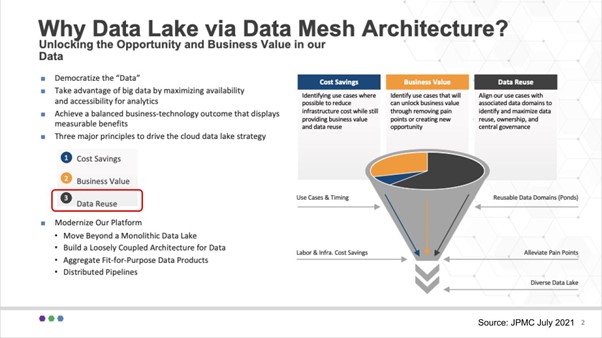
James Reid, the CIO, has produced a cloud-first strategy to modernize the JPMC platform. He focused on three factors of value: #1 Cut costs– always, of course. #2 Unlocking new opportunities or accelerating time to value. #3 data re-use as a fundamental value ingredient.
JPMC doesn’t try to force a single version of the truth by putting everything into a monolithic data lake. Rather it enables the business lines to create and own their own data lakes that comprise fit-for-purpose data products. And they use a catalogue of metadata to track lineage and provenance so that when they report to regulators, they can trust that the data they are communicating are current, accurate and consistent with previous disclosures.
Cloud-First Platform that Recognizes Hybrid
JPMC is leaning into public cloud and adopting agile methods and microservices architectures; and it sees cloud as a fundamental enabler. But it recognizes that on-prem data must be part of the data mesh equation.
Below is a slide that starts to get into some of the generic tech in play:
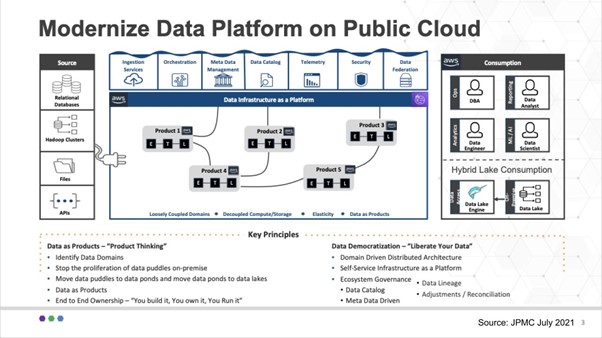
Data as a product (an end financial product for their clients) is a central mission within JPM. The data products live in business domains and are at the heart of the architecture. The databases, Hadoop clusters, files and APIs on the left-hand side serve the data product builders. The specialized roles on the right-hand side – the DBAs, data engineers, data scientists and data analysts serve the data product builders. Because the data products are owned by the business, they inherently have context.
One of the biggest points of contention on data mesh is and the use of a metadata catalogue to understand where data resides, the data lineage and overall change management, is of course essential.
Data as Products
Within the business domain, it will take time to understand what data as a product means and how to define or build the same. JPM struggled with the idea but came up with a summary of an approach.
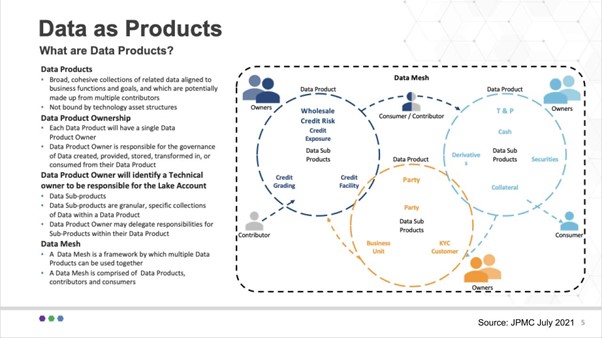
The above indicates that a common data model, a common data dictionary, is fundamental. For JPM it may take a lot of work to agree on what is a ‘transaction’. But you can see at a high level three product groups around Wholesale Credit Risk, Party and Trade & Position data as products. And each of these can have sub-products (e.g. KYC under Party). So, a key for JPMC was to start at a high level and iterate to get more granular over time.
Lots of decisions will need to be made around who owns the products and sub-products. The product owners had to defend why that product should exist, what boundaries should be put in place and what data sets do and don’t belong in the product. And which sub-products should be part of these circles. No doubt those conversations were engaging and perhaps sometimes heated as business line owners carved out their respective areas.
All of the data lakes and data flows would be platform inter-dependent and not resident on, or dependent on, a single platform or set of tooling (hybrid, multi-cloud).
Key Technical Considerations
This chart below shows a diagram of how JP Morgan thinks about the problem from a technology point of view.
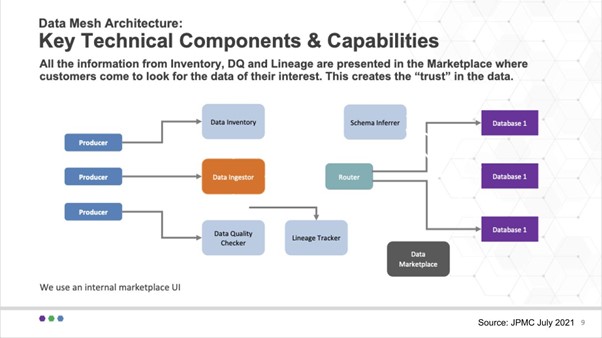
There are challenges:
- With various data stores how to write to these stores and move data from one to another?
- How can data be transformed (the mechanics, tooling, end schemas)?
- Where should the end data reside?
- Can the data be verified and audited?
- Who can access the data and what are the privileges allowed?
ETL, security access management, schema conversion and management, the registration of the data, and logging access and changes will of course be necessary. Many of these processes are tool dependent to some extent, probably pointing to the need for cross-platform or open-source tooling.
How JPMC Leverages the AWS Cloud for Data Mesh
The specific AWS implementation for JPM is below:
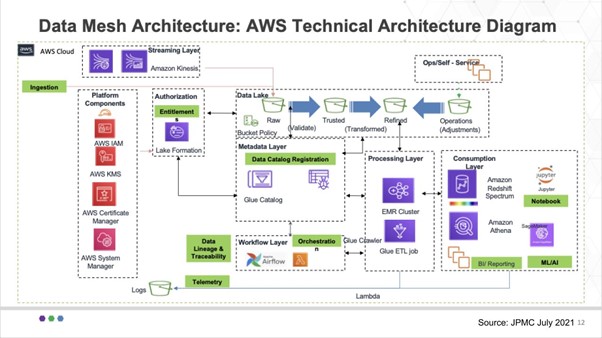
Start with the Authorization block right underneath Kinesis. The Lake Formation is the single point of entitlement for data product owners and has a number of buckets associated with it – including the raw area we just talked about, a trusted bucket, a refined bucket and a bucket for any operational adjustments that are required.
Beneath those buckets you can see the Data Catalog Registration block. This is where the Glue Catalog resides and it reviews the data characteristics to determine in which bucket the router puts the data. If for example there is no schema, the data goes into the Raw bucket and so forth, based on policy.
There are many AWS services in use here, identity, the EMR cluster from the legacy Hadoop work done over the years, Redshift Spectrum and Athena – JPMC uses Athena for single threaded workloads and Redshift Spectrum for nested types that can be queried independently of each other.
Now remember, very importantly, in this use case, there is not a single lake formation, rather multiple lines of business will be authorized to create their own lakes and that creates a challenge. In other words, how can that be done in a flexible manner to accommodate the business owners?
Note: Here’s an AWS-centric blog on how they recommend implementing data mesh
Enter Data Mesh
JPMC applied the notion of federated lake formation accounts to support its multiple lines of business. Each LoB can create as many data producer and consumer accounts as they desire and roll them up to their master line of business lake formation account shown in the center of each block below. And they cross connect these data products in a federated model as shown. These all roll up into a master Glue Catalogue seen in the middle of the diagram so that any authorized user can find out where a specific data element is located. This superset catalog comprises multiple sources and syncs up across the data mesh.
This approach includes some notion of centralized management but much of that responsibility has been passed down to the lines of business. It does roll up to a single master catalogue and that is a metadata management effort and seems compulsory to ensure federated and automated governance.
Importantly, at JPMC, the office of the Chief Data Officer is responsible for ensuring governance and compliance throughout the federation.
==END