Redundancy, Availability, Continuity, and Disaster Recovery
A key benefit of virtualising the infrastructure is to construct a platform which provides best-of-breed and reasonable, redundancy, availability and access; along with continuity and recovery. Most on-premise systems suffer from a lack of provisioning of these services, and moving to a cloud-virtualisation platform will certainly offer the opportunity to create a highly redundant and failure-proof system.
Redundancy
Redundancy is achieved through a combination of hardware and/or software with the goal of ensuring continuous operation even after a failure. Should a primary component fail for any reason, the secondary systems are already online and take over seamlessly. Examples of redundancy are multiple power and cooling modules within a server, a RAID-enabled disk system, or a secondary network switch running in standby mode to take over if the primary network switch fails.
High availability
High availability (HA) is the concept of maximizing system uptime to achieve as close to 100% availability as possible. HA is often measured by how much time the system is online versus unscheduled outages—usually shown as a percentage of uptime over a period of time. Goals for cloud providers and customers consuming cloud services are often in the range of 99.99% uptime per year. The SLA will determine what the cloud provider is guaranteeing and what outages, such as routine maintenance, fall out- side of the uptime calculation.
Many VMs, OSs, and applications will take longer than this just to boot up so HA configurations are necessary to achieve higher uptime requirements.
Key Take-Away
To keep your systems at the 99.99% level or better, you must design your system with redundancy and HA in mind. If you are targeting a lesser SLA, disaster recovery or standby systems might be adequate.
You can achieve the highest possible availability through various networking, application, and redundant server techniques, such as the following:
- Secondary systems (e.g., physical or VMs) running in parallel to the primary systems—these redundant servers are fully booted and running all applications—ready to assume the role of the primary server if it were to fail. The failover from primary to secondary is instantaneous, and causes no outages nor does it have an impact on the customer.
- Using network load balancers in front of servers or The load balancer will send users or traffic to multiple servers to maximize performance by splitting the workload across all available servers. The servers that are fed by the load balancer might be a series of frontend web or application servers.
- Of equal importance is that the load balancer skip, or not send traffic to a downstream server, if it detects that the server is offline for any reason; customers are automatically directed to one of the other available servers. More advanced load-balancing systems can even sense slow performance of their downstream servers and rebalance traffic to other servers to maintain a performance SLA (not just an availability SLA).
- Deploy clustered servers that both share storage and applications, but can take over for one another if one These servers are aware of each other’s status, often sending a heartbeat or “are you OK?” traffic to each other to ensure everything is online.
- Applications specifically designed for the cloud normally have resiliency built in. This means that the applications are deployed using multiple replicas or instances across multiple servers or VMs; there- fore, the application continues to service end users even if one or more servers fail.
The Figure below is an example of an HA scenario. In this example, a VM has failed and secondary VMs are running and ready to immediately take over operations. This configuration has two redundant servers one in the same datacenter on a separate server blade and another in the secondary datacenter. Failing-over to a server within the same datacenter is ideal and the least likely to impact customers. The redundant servers in the secondary datacenter can take over primary operations should multiple servers or the entire primary datacenter experience an outage.
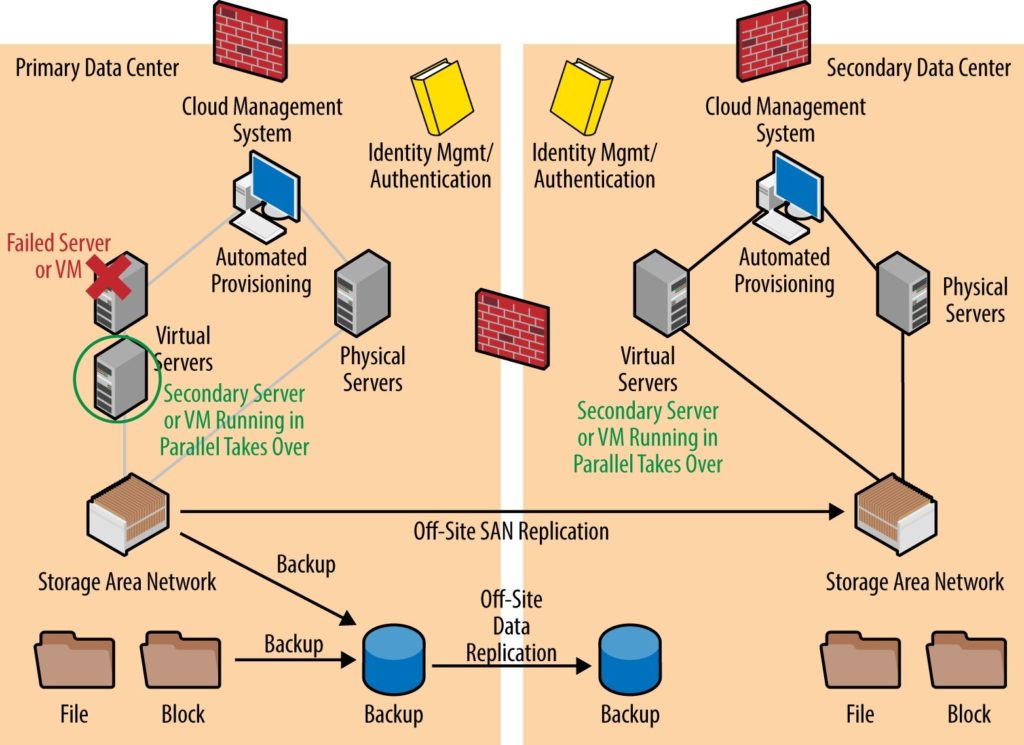
Example of HA: a failover
Continuity of operations
Continuity of operations (CoO) is the concept of offering services even after a significant failure or disaster. Essentially CoO is a series of failover techniques to keep network, servers, storage, and applications running and available. In the real world, CoO refers to a broader range of keeping your entire service online after a significant failure or disaster.
A continuity plan would typically involve failing-over to a secondary datacenter (or region in the example of AWS); in the event that the primary datacenter becomes unavailable or involved in a disaster. The network infrastructure, server farms, storage, and applications at the secondary datacenter are roughly the same as those in the primary, and most important, the data from the primary datacenter is always being replicated to the secondary.
This combination of having pre-staged infrastructure and synchronized data is what make it possible to continue servicing users. The failover time in such a scenario is sometimes measured in days however (much of DR must be manually induced), with some applications on-line in 4-6 hours.
Another part of a continuity plan deals with your staff and support personnel. If you must failover to a secondary datacenter, how will you adequately manage your cloud environment at that time? Will your staff be able to work from home if the primary office or datacenter location is compromised? The logistics and business plans are a huge part of a complete continuity of operations plan—it isn’t only about the technology.
Disaster recovery
A DR plan is similar to a CoO plan, but with one important addition. A DR plan also includes how to rebuild the datacenter, server farms, storage, network, or any portion that was damaged by the disaster event. In the case of a total datacenter loss, the DR plan might contain strategies to build a new datacenter in another cloud as well, an example would be to recreate your AWS architecture, through manual and automated configuration; in Azure.
Key Take-Away
The DR plan needs to document steps to bring the secondary datacenter up to its “primary” counterpart’s standards in the event that there is no hope of returning operations back to the primary. DR will and should remain a predominantly manual process – see below.
The figure below represents a scenario in which the primary datacenter has failed, lost connectivity, or is otherwise entirely unavailable to handle production customers. Due to the replication of data (through the SAN in this example) and redundant servers, all applications and operations are now shifted to the secondary datacenter. A proper CoO plan not only allows for the failover from the primary to secondary datacenter(s), but also documents a plan to either switch back all operations to the first datacenter after the problem has been resolved.
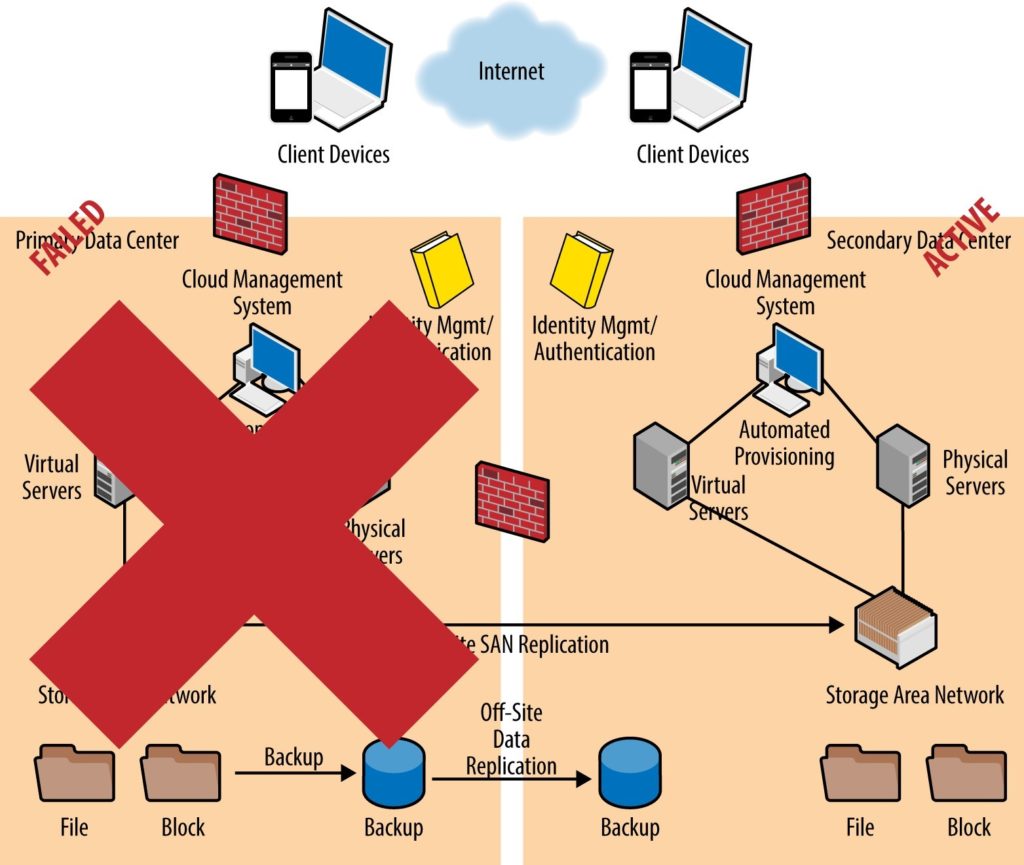
Figure: Example of disaster recovery—a continuity scenario
DR is mostly a manual process. There are many reasons for this:
- You can only test a real DR scenario by making a copy of your production environment. This is expensive and having a complete (3rd copy) of your environment, is financially impractical.
- You will need a dedicated team to test the failover to another region (in the case of AWS, Azure etc); and to fail back.
- You will need a dedicated team to replicate production data, AMIs, code, and scripts from the primary production environment to the DR region.
- You will only invoke DR in a disaster. This means that the primary site will be down for days, or weeks. If not a complete data-centre disaster, you are better off fixing in-situ.
- DR is a business decision and a business process. It should not be ‘automated’ in case the invocation is invalid or unnecessary.