Building and deploying highly available database systems involve many dimensions discussed here and here. There are also the considerations of indexing and clustering that this blog post covers.
DB Indexes and In-Memory Caching
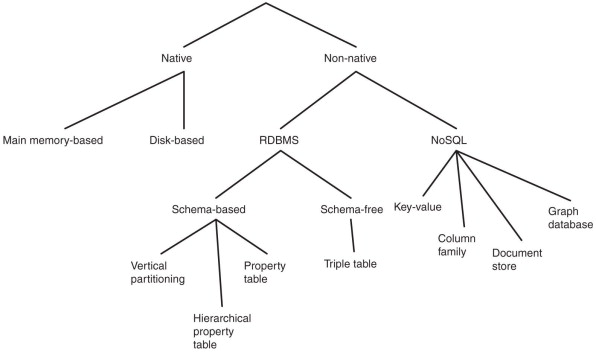
Polyglot databases refer to the fact that SQL and NoSQL datastores will co-exist. As with the main-frame the supposed death of SQL-RDBMS’ is grossly exaggerated. Even within NoSQL there is a general divergence of emphasis into 2 general groups. Document databases target use cases where data comes in self-contained documents (JSON) and the relationships between one document and another are rare (an example could be a CV). Graph databases go in the opposite direction, targeting use cases where anything is potentially related to everything and many-many relationships between documents are assumed. Again it is likely that both varieties of NoSQL could live happily within an Enterprise Architecture.
Schemas
One thing that document and graph databases have in common is that they typically don’t enforce a schema for the data they store, which can make it easier to adapt applications to changing requirements. However, most business applications still assume that data has a certain structure; it’s just a question of whether the schema is explicit (enforced on write) or implicit (assumed on read). Each data model comes with its own query language or framework: SQL, MapReduce, MongoDB’s aggregation pipeline, Cypher, SPARQL, or Datalog are some common examples.
RDMS Indexing
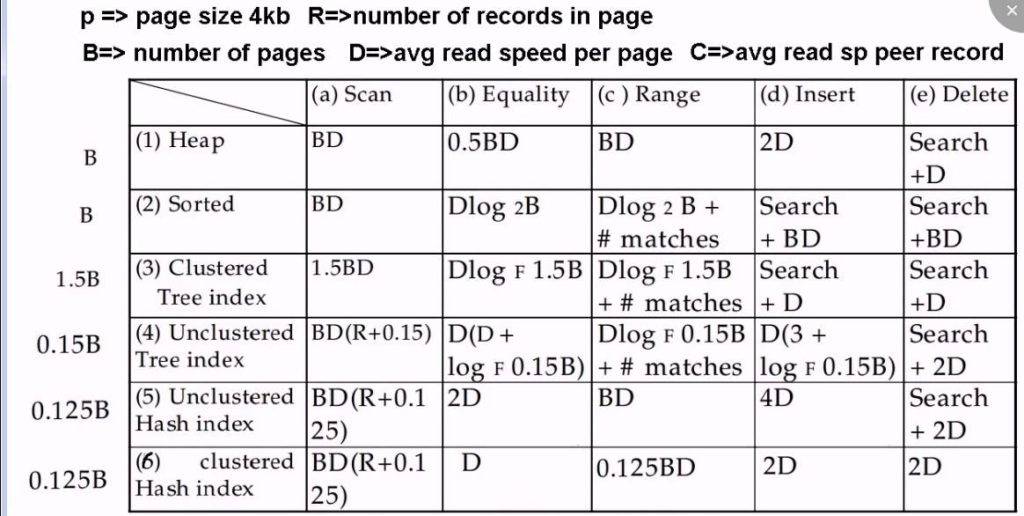
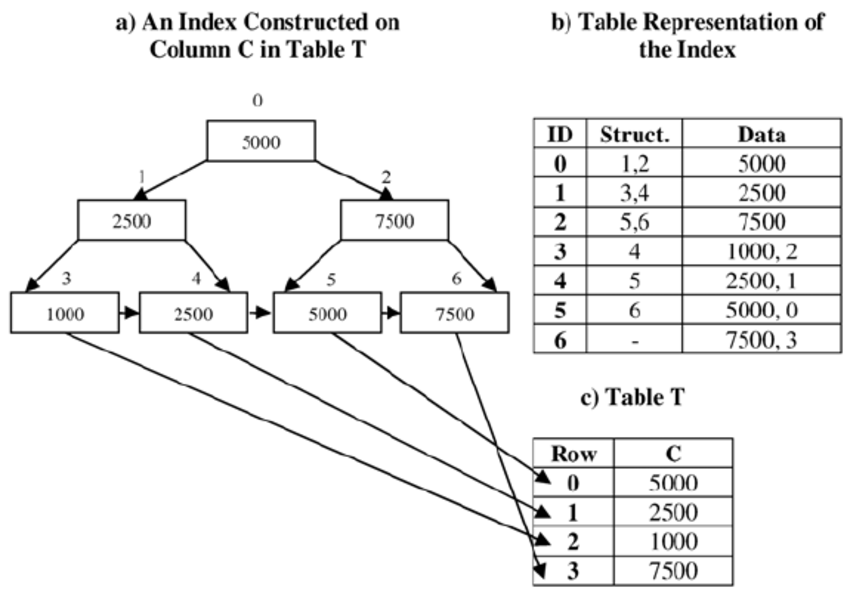
Indexing data in a retrievable format is a primary concern for a datastore. B-Trees are the most widely used indexing structure and remain the standard index implementation in almost all relational databases, with many nonrelational databases using them as well. B-trees keep key-value pairs sorted by key, which allows efficient key-value lookups and range queries. B-trees break the database down into fixed-size blocks or pages, traditionally 4 KB in size (sometimes bigger), and read or write one page at a time. This design corresponds more closely to the underlying hardware, as disks are also arranged in fixed-size blocks.
The B-Tree approach is different than log structured indexes (or LSM tree), which break the database down into variable-size segments, typically several megabytes or more in size, and always write a segment sequentially. Cassandra, BigData, Riak and other NoSQL variants use the LSM approach. The LSM tree is a data structure designed to provide low-cost indexing for files experiencing a high rate of inserts (and deletes) over an extended period. A good modern example might be incoming streaming data being written to a table.
Clustering and Non-Clustering Indexes
Clustering datastores and data itself is an important part of high availability. It can be of course, quite complicated. In many use cases a mixed approach is used. This compromise between a clustered index (storing all row data within the index) and a non-clustered index (storing only references to the data within the index) is known as a covering index or index with included columns, which stores some of a table’s columns within the index. This allows some queries to be answered by using the index alone (in which case, the index is said to cover the query). As with any kind of duplication of data, clustered and covering indexes can speed up reads, but they require additional storage and can add overhead on writes.
Databases also need to go to additional effort to enforce transactional guarantees, because applications should not see inconsistencies due to the duplication.
Multi-column indexes
The indexes discussed above only map a single key to a value. This model is insufficient if we need to query multiple columns of a table (or multiple fields in a document) simultaneously. The most common type of multi-column index is called a concatenated index, which simply combines several fields into one key by appending one column to another (the index definition specifies in which order the fields are concatenated). This is like an old-fashioned paper phone book, which provides an index from (lastname, firstname) to phone number. Due to the sort order, the index can be used to find all the people with a particular last name, or all the people with a particular lastname-firstname combination. However, the index is useless if you want to find all the people with a particular first name.
Multi-dimensional indexes
Multi-dimensional indexes are a more general way of querying several columns at once, which is particularly important for geospatial data. For example, a restaurant-search website may have a database containing the latitude and longitude of each restaurant. When a user is looking at the restaurants on a map, the website needs to search for all the restaurants within the rectangular map area that the user is currently viewing. This requires a two-dimensional range query:
SELECT*FROM restaurants WHERE latitude>51.4946 AND latitude< 51.5079 AND longitude > -0.1162 AND longitude < -0.1004;
A standard B-tree or LSM-tree index is not able to answer this kind of query efficiently. Normally they would give you either all the restaurants in a range of latitudes (but at any longitude), or all the restaurants in a range of longitudes (but anywhere between the North and South poles), but not both simultaneously. Besides the indexing of data in the datastore, there is the availability and organisation of data on the hard disk.
Data storage SSDs and In-Memory Computing
Solid State Drives or SSDs, store data on disk which needs to be laid out carefully if you want good performance on reads and writes. SSDs have two significant advantages: they are durable (their contents are not lost if the power is turned off), and they have a lower cost per gigabyte than RAM. As RAM becomes cheaper, the cost-per-gigabyte argument is eroded. Many datasets are simply not that big, so it’s quite feasible to keep them entirely in memory, potentially distributed across several machines. This has led to the development of in-memory databases. Some in-memory key-value stores, such as Memcached, are intended for caching use only, where it’s acceptable for data to be lost if a machine is restarted. This is temporal memory storage and is useful to decrease reads to the production database and reduce I/O writes and costs.
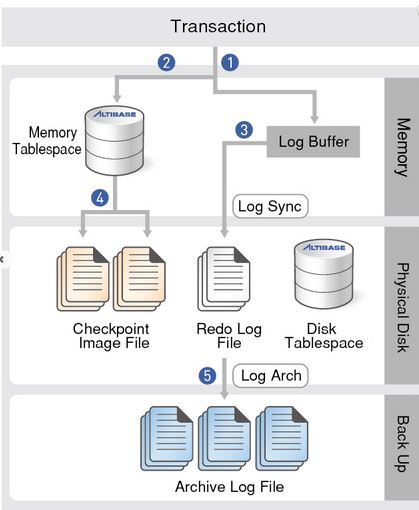
Memory and Durability
Unlike Memcached some memory databases aim for durability, which can be achieved with special hardware (such as battery-powered RAM), by writing a log of changes to disk, and by writing periodic snapshots to disk, or by replicating the in-memory state to other machines. When an in-memory database is restarted, it needs to reload its state, either from disk or over the network from a replica (unless special hardware is used). Despite writing to disk, it’s still an in-memory database, because the disk is merely used as an append-only log for durability, and reads are served entirely from memory. Writing to disk also has operational advantages: files on disk can easily be backed up, inspected, and analysed by external utilities.
Benefits of In-Memory Computing
Counterintuitively, the performance advantage of in-memory databases is not because they don’t need to read from disk. Even a disk-based storage engine may never need to read from disk if you have enough memory, because the operating system caches recently used disk blocks in memory anyway. Rather, In Memory cache dbs can be faster because they can avoid the overheads of encoding in-memory data structures in a form that can be written to disk.
In summary the type of data indexing chosen (natively offered by the datastore of choice), is an important consideration when architecting highly available database solutions. Likewise, in memory computing is now a common pattern to provide faster response times and decrease I/O usage and cost. There are different cache patterns depending on the product chosen. Another important consideration for the next blog post will be OLAP vs OLTP models of database implementation.
==End