Amazon RDS (Relational Database Service) RDS is a managed relational database service that supports various database engines such as MySQL,…
Amazon Redshift Redshift is a fully managed data warehousing service designed for online analytical processing (OLAP) workloads. It is optimized…
On real world projects and deployments, you hear the lament that a datawarehouse or data engine ‘does not work’. Query…
Amazon S3 Iceberg Tables introduced fully managed Apache Iceberg table support to S3, optimizing the storage and querying of tabular…
There are a wide variety of databases. With cloud and hybrid architectures often see the following: Relational DB A structured format with rows…
A useful architecture to move data from on-premises to AWS is to consider using AWS S3 outputs and move data…
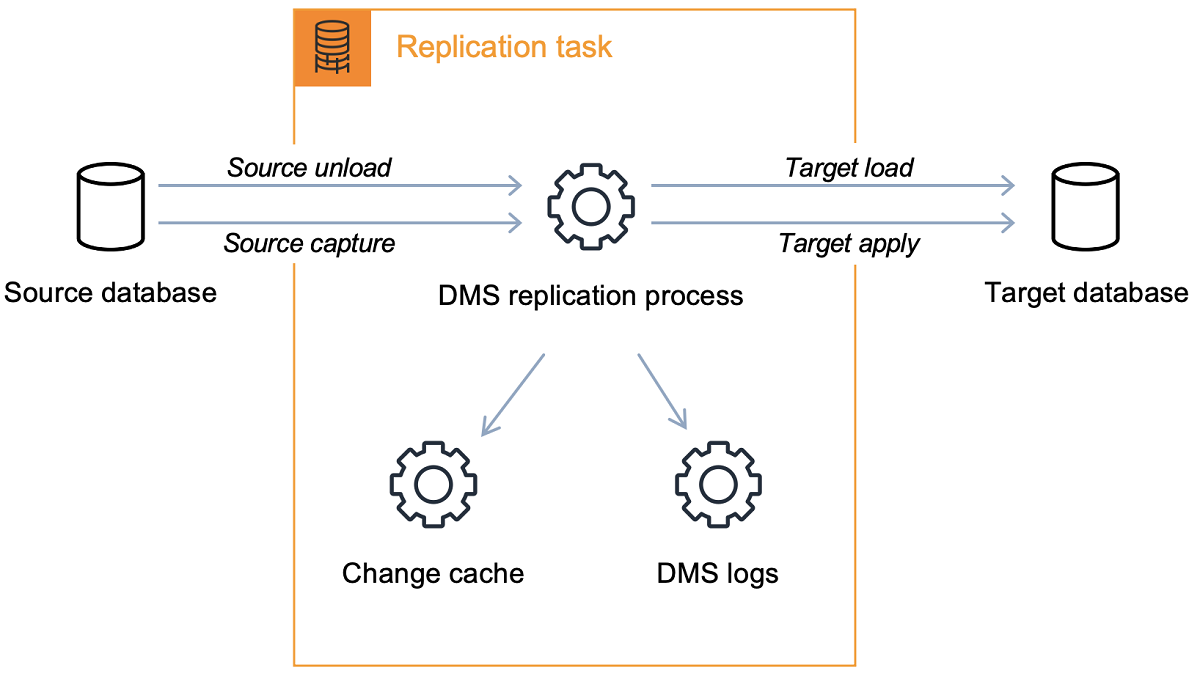
AWS Database Migration Service or DMS is a mature process to move on premises data to the AWS cloud, including…
The problems with Data Pipelines and the hydration of a Data Lake include: Data teams often end with technical debt surrounding…
In essence Data Operations is based on DevSecOps or DevOps and applies these same ideas to the life cycle of…
DataLake The entire concept of a Data Operations Platform rests on top of a Data Lake. There is no simple…