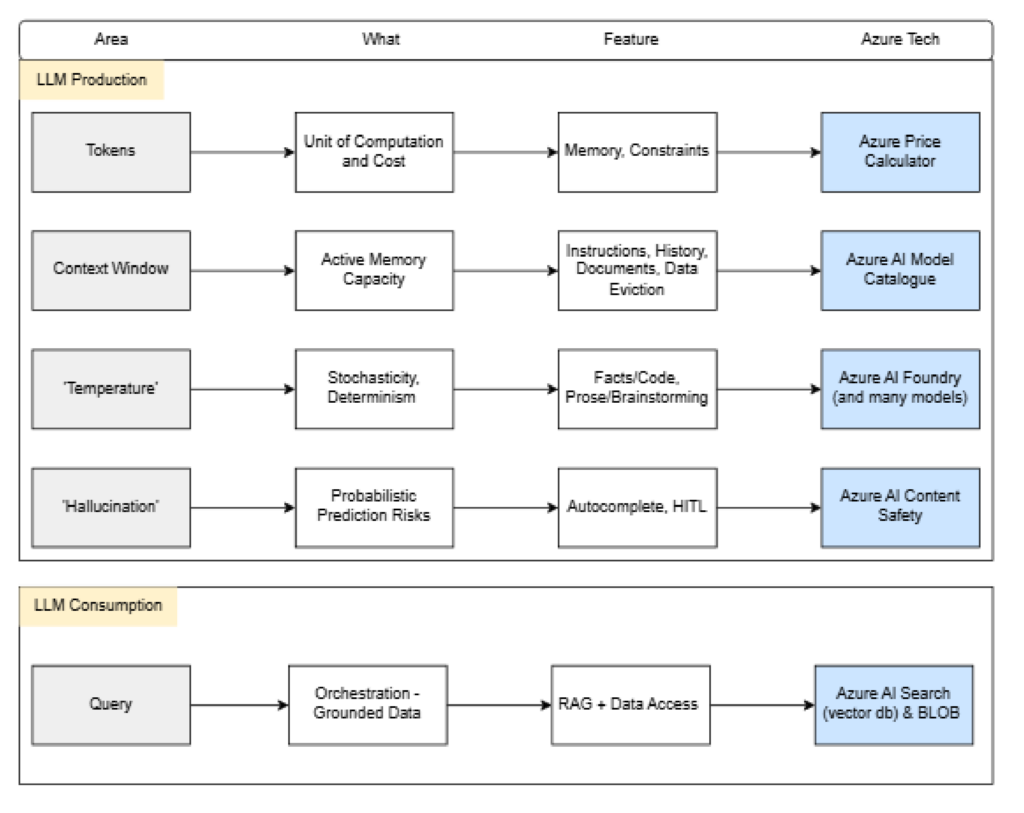
The below outlines the 5 main pillars of using an AI LLM. The terminology is the basis of discussing ‘AI’ within an enterprise.
1. Tokenization: Unit of Computation
To understand AI performance and cost, one must first recognize that models do not process raw text in the form of words or characters. Instead, they operate on tokens which are atomic units of data representing discrete sequences of characters.
- Definition: A token can encompass a single word, a common prefix (e.g., “un-“), a suffix (e.g., “-tion”), or even individual punctuation marks.
- Cost Impact: Cloud service providers and API architectures measure consumption in tokens. Every input sent and every output generated incurs a cost based on these counts.
- Operational Limit: Tokens are the primary constraint of a model’s memory. When a conversation exceeds a specific token threshold, the model must evict the oldest data to make room for new inputs, similar to how a computer manages RAM.
2. The Context Window: Active Memory Capacity
The Context Window represents the maximum quantity of tokens a model can maintain in its active memory at any given moment. This serves as the model’s immediate workspace.
- Scope: This window must contain the user’s initial instructions (system prompts), the ongoing conversation history, any uploaded documents, and the model’s pending response.
- Evolution of Scale: Early iterations of LLMs were restricted to small windows (roughly 4,000 tokens), limiting them to short interactions. Modern frontier models now support windows exceeding one million tokens, enabling the analysis of entire codebases or multi-volume manuscripts in a single session.
- Strategic Limitation: If an AI seems to forget a detail from earlier in a session, it is usually because that information has shifted outside the context window’s boundaries.
3. Temperature: Stochasticity vs. Determinism
Temperature is a configuration parameter that governs the degree of randomness or creativity in a model’s response. It determines the probability distribution used when the AI selects the next token.
- Low Temperature (Approaching 0): The model becomes deterministic, consistently selecting the most statistically probable token. This is ideal for technical documentation, code generation, and factual summarization where precision is paramount.
- High Temperature (Approaching 1.0+): The model takes statistical risks, choosing less likely tokens to produce more diverse and creative prose. This is highly effective for brainstorming, marketing copy, and creative writing.
- Application: Most consumer interfaces use a balanced default (approx. 0.7), but professional developers manually tune this to align the output with the specific business requirement.
4. Hallucination: Probabilistic Prediction Risks
A Hallucination occurs when an LLM generates factually incorrect information while maintaining a tone of absolute certainty. To mitigate this risk, one must understand that LLMs are not traditional databases.
- Mechanism: LLMs function as sophisticated next-token predictors. They do not look up facts; they calculate the most likely sequence of language based on patterns identified during training.
- The Confidence Gap: Because the model is trained to provide fluid, helpful responses, it may prioritize linguistic coherence over factual accuracy if it lacks specific data. It will complete the pattern even if the resulting facts are non-existent.
- Verification Requirement: In high-stakes environments legal, medical, or financial AI output should be treated as a draft that requires human-in-the-loop validation.
5. RAG: Retrieval-Augmented Generation
RAG is an architectural framework designed to solve two primary LLM limitations: knowledge cutoff (the model only knows what it was trained on) and a lack of access to private, proprietary data.
- The Process: Rather than retraining a massive model on new data, RAG allows the system to search a specific set of documents (such as your company’s internal PDFs) in real-time.
- Vector Databases: When a query is submitted, the system retrieves the most relevant chunks of information from a specialized database.
- Grounding: These retrieved facts are fed into the model alongside the user’s question. The AI is then instructed to answer only using that provided context, effectively grounding the response in verified facts and significantly reducing the likelihood of hallucination.
Executive Summary Checklist
| Concept | Business Implication | Microsoft Tooling |
| Tokens | Direct Driver of API Costs | Azure Price Calculator |
| Context Window | Limits Document Analysis Size | Azure AI Model Catalog |
| Temperature | Balance of Accuracy vs. Innovation | Azure AI Foundry Playground |
| Hallucination | Risk Management & Verification | Azure AI Content Safety |
| RAG | Unlocks Proprietary Data Value | Azure AI Search & Blob Storage |
==
Microsoft Links
1. Tokenization
Understanding how Microsoft handles tokens is critical for capacity planning and cost management.
- Concepts: Tokens and Tokenization in Azure OpenAI
- Tool: OpenAI Tokenizer Web Tool (Useful for visualising how text is chunked).
2. Context Window
Microsoft provides specific limits for each model version (e.g., GPT-4o, o1) within the Azure environment.
- Model Limits: Azure OpenAI Service Models & Context Windows
- Quotas: Manage and View Azure OpenAI Service Quotas
3. Temperature & Parameters
In the Azure AI Foundry (formerly AI Studio), Temperature is part of the inference configuration.
- Configuration: Azure OpenAI Chat Completion Parameters
- Best Practices: System Message Framework and Prompt Engineering
4. Hallucination & Safety
Microsoft addresses hallucinations through Groundedness and automated safety guardrails.
- Safety Services: Azure AI Content Safety Overview
- Evaluation: Monitoring and Evaluating Generative AI Quality
5. RAG (Retrieval-Augmented Generation)
This is the Gold Standard for enterprise AI, often implemented using Azure AI Search.
- Architecture: Retrieval-Augmented Generation (RAG) in Azure AI Search
- Implementation: Using your data with Azure OpenAI Service