Data Lake Architecture
Data lake architecture was introduced in 2010 in response to the challenges of data warehousing architecture in satisfying the new uses of data: access to data by data scientists in the machine learning model training process.
Data scientists need data in its original form for the machine learning (ML) model training process. ML Models also require massive loads of data, which can be hard to store in a data warehouse.
- The first data lakes built involved storing data in the Hadoop Distributed File System (HDFS) across a set of clustered compute nodes. Data would be extracted and processed using MapReduce, Spark and other data processing frameworks.
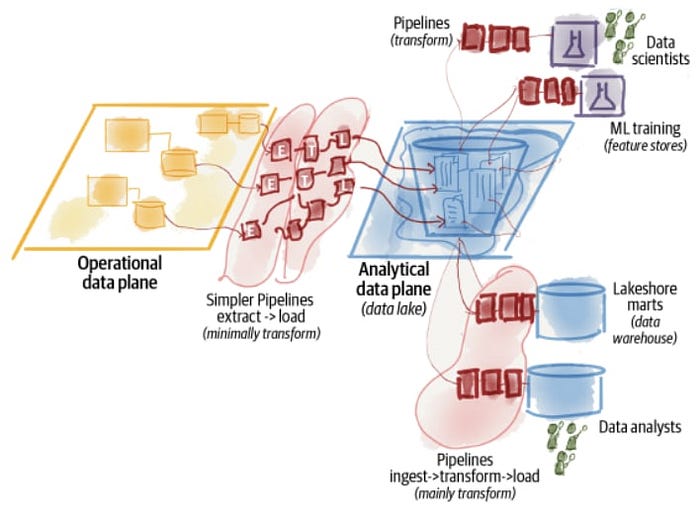
Data lake architecture works under the ELT process, rather than the ETL process. Data gets extracted (E) from operational systems and loaded (L) into a central storage repository. However, unlike data warehousing, a data lake assumes very little or no transformation and modeling of the data upfront. The goal is to retain the data close to its original form. Once the data enters the lake, the architecture gets extended with data transformation pipelines (T) to model the raw data and store it in the data warehouse or feature stores.
Data engineering teams, to better organize the lake, create different “zones”. The goal is to store the data according to the degree of cleansing and transformation, from the rawest data to data enrichment steps, to the cleanest and most accessible data.
This data architecture aims to improve the ineffectiveness and friction of extensive up-front modeling that data warehousing requires. The up-front transformation is a blocker and leads to slower iterations for data access and model training.
Main challenges of this approach:
- Data lake architecture suffers from complexity and deterioration resulting in poor data quality and reliability.
- Complex pipelines of batch or streaming jobs operated by a central team of hyper-specialized data engineers.
- It creates unmanaged datasets, which are often untrusted and inaccessible, providing little value
- The data lineage and dependencies are hard to track
- Having no extensive up-front data modeling creates difficulties to build a semantic mapping between different data sources, generating data swamps.
Cloud Data Lake Architecture
The biggest changes from second-generation to third-generation data architecture were the switch to the cloud, the real-time data availability, and the convergence between the data warehouse and the data lake. In more detail:
- Support streaming for near real-time data availability with architectures such as Kappa.
- Attempt to unify batch and stream processing for data transformation with frameworks such as Apache Beam.
- Fully embrace cloud-based managed services and use modern cloud-native implementations with isolated computing and storage. Storing data becomes much cheaper.
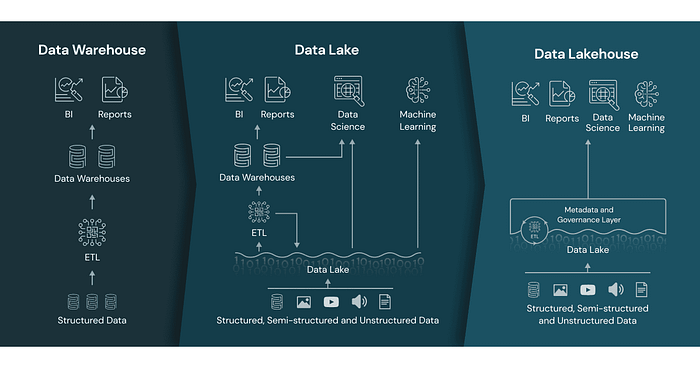
- Converge the warehouse and lake into one technology, either extending the data warehouse to include embedded ML training or alternatively building data warehouse integrity, transactionality, and querying systems into data lake solutions. Databricks Lakehouse is an example of a traditional lake storage solution with warehouse-like transactions and query support.
The cloud data lake is addressing some of the gaps of the previous generations. Yet, some challenges remain:
- Data lake architecture remains very complex to manage, affecting data quality and reliability.
- The architecture design remains centralized requiring a team of hyper-specialized data engineers.
- Long time for insights. Data consumers continue to wait several months to get a dataset for analytics or machine learning use cases.
- Data warehouses no longer are a replication of the real world through data, impacting data consumers experience while exploring data.
All of those challenges led us to the fourth-generation data architecture named ‘Data Mesh’ a federated, decentralised approach to data management which attempts to avoid the issues listed above, but will add complexity in access including Role Based, Tag Based and fine-grain data table and column access.