Object store – region-based storage resource in AWS.
Amazon S3 is intentionally built with a minimal feature set that focuses on simplicity and robustness. Following are some of the advantages of using Amazon S3:
- Creating buckets – Create and name a bucket that stores data. Buckets are the fundamental containers in Amazon S3 for data storage.
- Storing data – Store an infinite amount of data in a bucket. Upload as many objects as you like into an Amazon S3 bucket. Each object can contain up to 5 TB of data. Each object is stored and retrieved using a unique developer-assigned key.
- Downloading data – Download your data or enable others to do so. Download your data anytime you like or allow others to do the same.
- Permissions – Grant or deny access to others who want to upload or download data into your Amazon S3 bucket. Grant upload and download permissions to three types of users. Authentication mechanisms can help keep data secure from unauthorized access.
- Standard interfaces – Use standards-based REST and SOAP interfaces designed to work with any internet-development toolkit.
Policies
Security is Policy based. Secure the Bucket Policies using JSON templates.
1-Within the policy the assumption is that the request is denied.
2-All attached policies are evaluated.
3-Explicit deny is given a priority over allow.
4-If explicit deny is not found, the code will look for an allow-instruction.
5-If no allow is found, the request is denied.
Resource types defined by Amazon S3
The following resource types are examples which are used in the Resource element of IAM permission policy statements. Each action in the Actions table identifies the resource types that can be specified with that action. A resource type can also define which condition keys you can include in a policy. These keys are displayed in the last column of the table. For details about the columns in the following table, see The resource types table.
| Resource types | ARN | Condition keys |
| accesspoint | arn:${Partition}:s3:${Region}:${Account}:accesspoint/${AccessPointName} | |
| bucket | arn:${Partition}:s3:::${BucketName} | |
| object | arn:${Partition}:s3:::${BucketName}/${ObjectName} | |
| job | arn:${Partition}:s3:${Region}:${Account}:job/${JobId} |
ACLs
Every bucket has an ACL. You can use ACL policies to deny access or allow access to the bucket for particular users, roles and groups. When a request is received to access an object (example a video or image), the ACL rules are checked. When you create a bucket you are automatically granted by default, full administrative privileges.
AWS provides ‘canned’ ACLs with permission policies attached. An example is ‘Private’, the owner has full control over the bucket, no one else can access the bucket. This is the default policy. You can change this to ‘Public-Read’ to allow other users to read objects.
IPs and Accounts
You can change the policies to allow IP addresses to access the Bucket and objects; or other AWS accounts.
Example: Trusted IP list is uploaded to S3 only
S3 based on IP address
- {
- “Version”: “2012-10-17”,
- “Id”: “S3PolicyId1”,
- “Statement”: [
- {
- “Sid”: “IPAllow”,
- “Effect”: “Allow”,
- “Principal”: “*”,
- “Action”: “s3:*”,
- “Resource”: “arn:aws:s3:::examplebucket/*”,
- “Condition”: {
- “IpAddress”: {“aws:SourceIp”: “54.240.143.0/24”}
- }
Cross Account S3 (access the S3 bucked in Account A, from another Account B)
- {
- “Version”: “2012-10-17”,
- “Statement”: [
- {
- “Sid”: “111”,
- “Effect”: “Allow”,
- “Principal”: {
- “AWS”: “arn:aws:iam::453314488441:root”
- },
- “Action”: “s3:*”,
- “Resource”: [
- “arn:aws:s3:::demo-crossover”,
- “arn:aws:s3:::demo-crossover/*”
- ]
Use with CloudFront
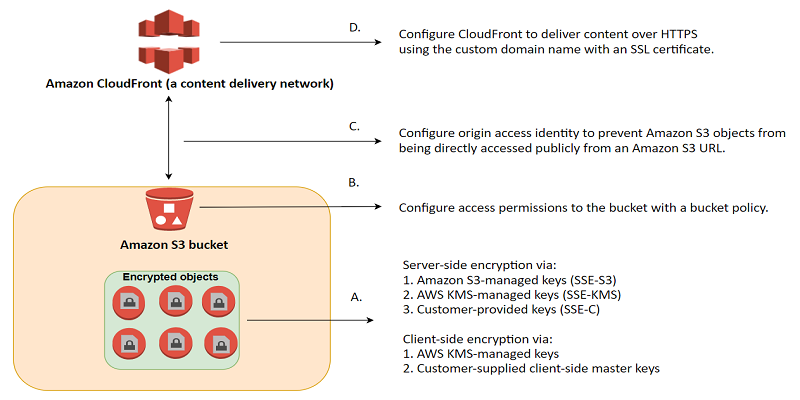
In order to protect access to S3 bucket objects, you may deploy Cloud Front (CDN) as the Origin of Identity, where users must certify their permissions. This means requiring users to use special CloudFront Signed URLs to access the content, not the standard CloudFront public URLs and not allowing them direct access to S3 URLs.
You can follow AWS’ outline in Using an Origin Access Identity to Restrict Access to Your Amazon S3 Content, so that users are unable to leak/guess S3 URLs and are required to go through CloudFront and not have the ability to bypass CloudFront.
S3 Versioning
Many companies that distribute content via the Internet want to restrict access to documents, business data, media streams, or content that is intended for selected users, for example, users who have paid a fee. To securely serve this private content using CloudFront, you can enable Bucket versioning. Example: Object photo1.gif ID: 1111 was updated today is now photo1.gif ID = 2222. This helps to audit object changes, deletions or unauthorised access (and take action). All S3 API activity should be monitored by S3 access logs (using CloudTrail logs, deployed to an S3 bucket for analysis).
S3 Cross Region Replication
For compliance and to protect data from being deleted you should enable cross-region replication automatically in either the console or CLI. Extra storage charges will apply.
Encryption
You need to encrypt data into S3 over the wire (CLI, KMS, TLS), and at rest via SSE-S3 encryption.
2 basic methods to do this.
1-Server Side Encryption or SSE – request AWS to encrypt the object before saving it on disks. Decrypt when you use the object (decryption is provided automatically).
2-SSE with Key Management Service (KMS) a managed AWS key service which generates AES asymmetric keys using the Cloud Hardware Security Module managed by AWS.
3-Client Side or CSE – Encrypt data on the client and upload to S3. You manage the process, keys.
Example: SSE-S3 encrypts data at rest using 256-bit Advanced Encryption Standard (AES-256). Each object is encrypted with a unique data/object key and each data/object key is further encrypted using a master key (envelope encryption) which is regularly rotated so as to prevent data getting compromised. Unlike SSE-KMS there are no additional charges for using SSE-S3 in addition to the storage that you are using on S3.
Example of SSE:
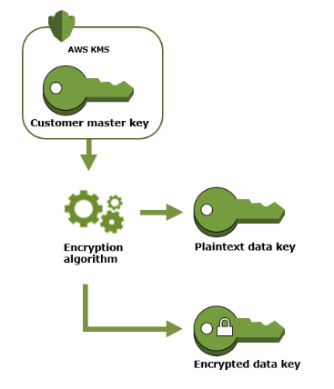
To encrypt the objects you need a data key. Now to generate a data key you can specify a CMK (Customer Master Key) that you have already created otherwise S3 will request AWS KMS to create a default CMK which can be used to create a data key.
Process:
Same process for SSE-S3, SSE-KMS, and SSE-C. AWS images.
The CMK (customer master key) uses the encryption algorithm (AES-256) and creates two keys, one is plaintext data key and the other is encrypted data key.
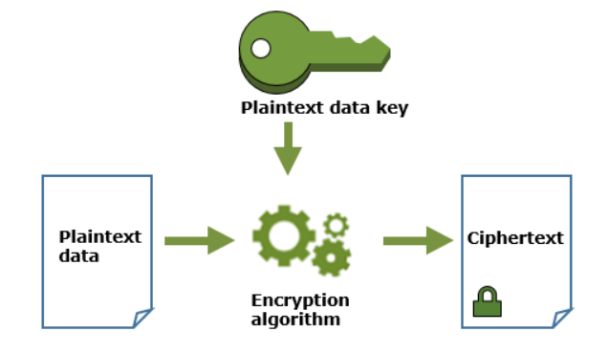
S3 encrypts the object with plaintext data key and deletes the key from memory. The encrypted object along with the encrypted data key is then stored in S3.
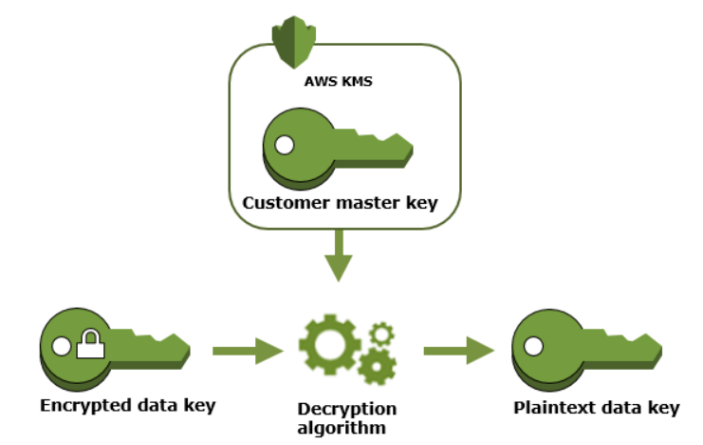
While retrieving the object S3 sends the encrypted data key to KMS. KMS matches the correct CMK then it decrypts the encrypted data key and sends the plaintext data key to S3. S3 then retrieves the object by decrypting the object with this plaintext data key.
See https://docs.aws.amazon.com/kms/latest/developerguide/concepts.html
SSE and KMS
SSE-KMS is similar to SSE-S3 but comes with some additional benefits over SSE-S3. Unlike SSE-S3 you can create and manage encryption keys yourself or you can use a default CMK key that is unique to you for the service that is being used (S3 in this case) and the region you are working in.
When you create a CMK using KMS instead of using default CMK you get more flexibility as you can create, rotate and disable the encryption keys. As KMS is integrated with Cloudtrail with SSE-KMS you can also audit the usage of the key like when, by whom, for what purpose the key was used. You can also give separate permissions for the use of an envelope key.
You can choose to have AWS KMS automatically rotate CMKs every year, provided that those keys were generated within AWS KMS HSMs. Automatic key rotation is not supported for imported keys, asymmetric keys, or keys generated in an AWS CloudHSM cluster using the AWS KMS custom key store feature. If you choose to import keys to AWS KMS or asymmetric keys or use a custom key store, you can manually rotate them by creating a new CMK and mapping an existing key alias from the old CMK to the new CMK.
SSE with Customer managed keys (SSE-C)
With SSE-C, the client manages the encryption keys itself whereas AWS manages the encryption/decryption part. There are no additional charges like SSE-S3. A client has to send the encryption key along with the object to be uploaded in a request. S3 then encrypts the object using the provided key and the object is stored in S3. Note that the encryption key is deleted from the system.
When the user wants to download or retrieve the object it must supply the encryption key in the request. S3 first verifies that it is the correct encryption key, after the successful match it decrypts the object and returns it to the Client.
==END