Amazon Redshift is a petabyte scalable columnar data warehouse that is very efficient in storing raw data and collecting data from various sources. Redshift supports automated tasks for configuring, monitoring, backing up, and securing a data warehouse.
Redshift Spectrum is the ability to perform analytics directly on the data in the Amazon S3 cluster using a Redshift node. In essence Spectrum is an advanced analytical tool that works on top of Redshift. It offers more functionality and efficiency when compared to the Redshift analytical tooling.

Summary:
- Redshift Spectrum is a feature of the Amazon Redshift data warehouse.
- Spectrum is built for fast, complex, and efficient analysis of objects stored S3.
- Spectrum eliminates the requirement to move S3 data to a database.
- Spectrum can directly query data inside the S3 bucket.
- Spectrum supports complex data files such as JSON, ORC, Parquet, as well as complex data types such as maps, arrays, and structures.
- Spectrum is fully managed.
How does Redshift Spectrum work?
- Redshift Spectrum divides user queries into filtered subsets that run concurrently.
- These requests are distributed across thousands of AWS-managed nodes to maintain query speed and consistent performance.
- Redshift Spectrum can be scaled to query over exabytes of data, and when S3 data is aggregated, it’s sent back to the Redshift cluster for final processing.
- Redshift Spectrum requires a SQL client connected to the Redshift cluster.
- Multiple clusters can access the same S3 dataset at the same time, but you can only query data stored in the same AWS Region.
- Redshift Spectrum can be used in combination with other AWS computing services that have direct access to S3, such as Amazon Athena, Amazon Elastic Map Reduce for Apache Spark, Apache Hive, and Presto.
Architectures
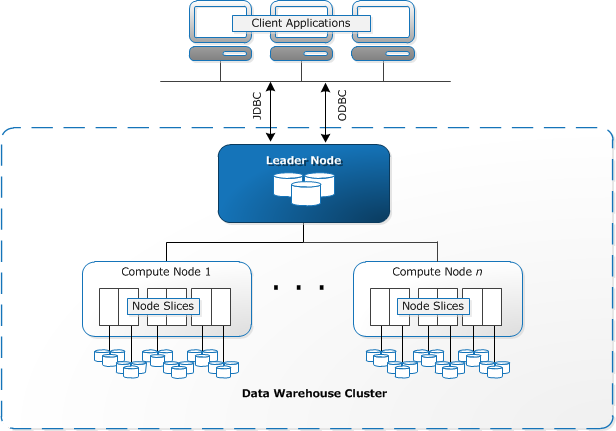
A Redshift architecture consists of two or more Computing Nodes that are connected to a Leader Node. All the communication between client applications and Cluster only happens through the Leader Node.

Image Source: docs.aws.amazon.com
{kind=link}
Redshift spectrum works on top of the Redshift architecture. It is added after the storage Phase.

Image Source: cloudfront.net
{kind=link}
In summary Amazon Redshift Spectrum is a great tool for easily executing complex SQL queries against data stored in Amazon S3.
Cross account access
- Only within the same region
- Only Spectrum to S3
- Glue Data Catalog in Account B eg create a Glue crawler in Account B to crawl the same customer data and create a table to query from Spectrum
- Glue Data Catalog in Account A
Current Estate:

Option 1:

Option 2:

External schema created
drop schema if exists spectrumxacct2;
create external schema spectrumxacct2
from data catalog
database ‘spectrumdb_account_a’
iam_role ‘<ARN for IAM role redshift_role_account_b from Account B,<ARN for IAM role xacct_kms_role_account_a from Account A>’
create external database if not exists;
run the query against account A — select * from spectrumxacct2.customer limit 10;