There are many reasons why NoSQL appeared in the last decade creating what many would call the capability to produce a ‘polyglot’ data architecture. The driving forces behind the adoption of NoSQL databases, would include:
A need for greater scalability than SQL DBs can easily achieve, including very large datasets or very high write throughput:
- A widespread preference for free and open source software over commercial database products;
- Specialized query operations that are not well supported by the relational model;
- Frustration with the restrictive schemas of relational DBs, and a desire for a more dynamic and expressive data model.
Different applications have different requirements, and the best choice of technology for one use case may well be different from the best choice for another use case. It therefore seems likely that in the foreseeable future, relational databases will continue to be used alongside a broad variety of non-relational datastores — an idea that is sometimes called polyglot persistence.
Relational merits
The relational model lays out all the data in the open: a relation (table) is simply a collection of tuples (rows). There are no labyrinthine nested structures, no complicated access paths to follow if you want to look at the data. You can read any or all of the rows in a table, selecting those that match an arbitrary condition. You can read a particular row by designating some columns as a key and matching on those. You can insert a new row into any table without worrying about foreign key relationships to and from other tables.
The key advantage offered by RDMS over NoSQL is that of ACID transactions (atomic, consistent, isolated, durable), which is the basis of transaction handling systems and necessary for high-end computing, reliability of data inter-change and the ability to rollback.
Another key difference is that in a relational database, the query optimizer automatically decides which parts of the query to execute in which order, and which indexes to use. Those choices are effectively the “access path,” but the big difference is that they are made automatically by the query optimizer, not by the application developer, so we rarely need to think about them. If you want to query your data in new ways, you can just declare a new index, and queries will automatically use whichever indexes are most appropriate. You don’t need to change your queries to take advantage of a new index. (See also “Query Languages for Data”.)
The relational model thus made it much easier to add new features to applications. Query optimizers for relational databases are complicated beasts, and they have consumed many years of research and development effort. But a key insight of the relational model was this: you only need to build a query optimizer once, and then all applications that use the database can benefit from it. If you don’t have a query optimizer, it’s easier to handcode the access paths for a particular query than to write a general-purpose optimizer — but the general-purpose solution wins in the long run.
OO vs SQL
Today however, most application development is done in object-oriented programming languages, not sequential languages, which leads to a common criticism of the SQL data model: if data is stored in relational tables, an awkward translation layer is required between the objects in the application code and the database model of tables, rows, and columns. The disconnect between the models is sometimes called an ‘impedance mismatch.’ Hibernate and other ORD (object relational data) mapping tools exist to overcome this mis-match.
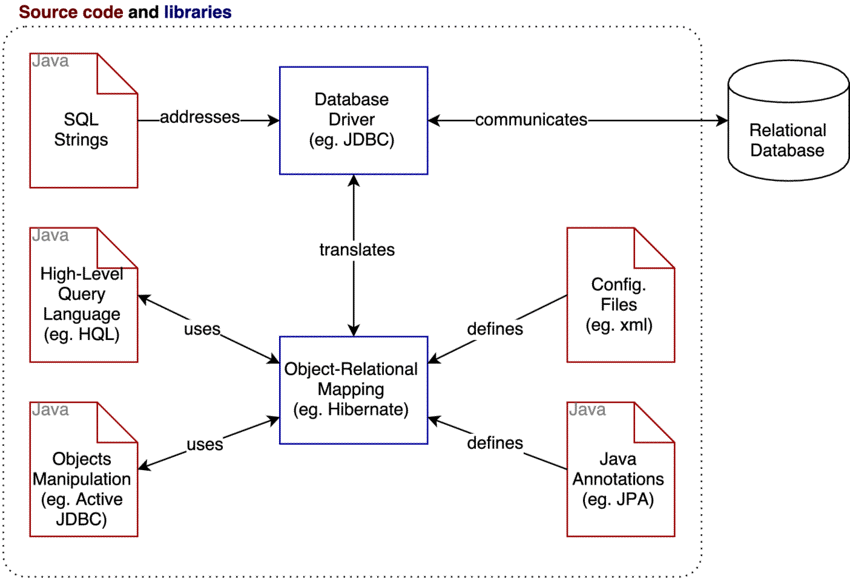
NoSQL database systems, named Document DBs, are an attempt to overcome that impedance mismatch.
Document DBs, JSON
Some data can fit nicely into a schema-less, or a NoSQL format. For a data structure with a tree pattern like for instance a CV or résumé, which is mostly a self-contained document, a JSON or Java-Script Object Notation representation can be appropriate. JSON has the appeal of being much simpler than XML. Document-oriented databases like MongoDB, CouchDB, and Espresso support this data model.
JSON may indeed reduce some of the mismatch between the application code and storage layer. But there are also some issues with the JSON data encoding format. However, the lack of a schema is often cited as an advantage and the JSON representation has better locality than the multi-table schema. If you want to fetch a profile in the relational example, you need to either perform multiple queries (query each table by user_id) or perform a messy multi-way join between the users table and its subordinate tables.
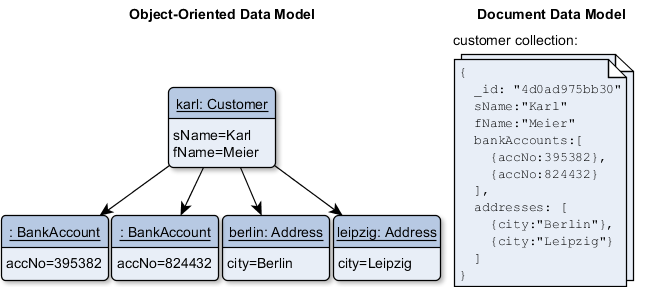
Schema flexibility in the document model
Most document databases, and the JSON support in relational databases, do not enforce any schema on the data in documents. XML support in relational databases usually comes with optional schema validation. No schema means that arbitrary keys and values can be added to a document, and when reading, clients have no guarantees as to what fields the documents may contain. Document databases are sometimes called schemaless, but that’s misleading, as the code that reads the data usually assumes some kind of structure — i.e., there is an implicit schema, but it is not enforced by the database.
A more accurate term is schema-on-read (the structure of the data is implicit, and only interpreted when the data is read), in contrast with schema-on-write (the traditional approach of relational databases, where the schema is explicit and the database ensures all written data conforms to it). Schema-on-read is similar to dynamic (runtime) type checking in programming languages, whereas schema-on-write is similar to static (compile-time) type checking. Just as the advocates of static and dynamic type checking have big debates about their relative merits, enforcement of schemas in database is a contentious topic, and in general there’s no right or wrong answer.
Data locality for queries
A document is usually stored as a single continuous string, encoded as JSON, XML, or a binary variant thereof (such as MongoDB’s BSON). If your application often needs to access the entire document (for example, to render it on a web page), there is a performance advantage to this storage locality. If data is split across multiple tables, multiple index lookups are required to retrieve it all, which may require more disk seeks and take more time. The locality advantage only applies if you need large parts of the document at the same time. The database typically needs to load the entire document, even if you access only a small portion of it, which can be wasteful on large documents. On updates to a document, the entire document usually needs to be rewritten — only modifications that don’t change the encoded size of a document can easily be performed in place. For these reasons, it is generally recommended that you keep documents fairly small and avoid writes that increase the size of a document. These performance limitations significantly reduce the set of situations in which document databases are useful.
One to Many
In the CV example there are one-to-many relationships from the user profile to the user’s positions, educational history, and contact information. This implies a tree structure in the data, and the JSON representation makes this tree structure explicit and easy to store.
However, many systems are far more complicated than a simple tree structure. If we were to build a system of CVs at an aggregate regional level, the tree structure and storage becomes problematic. Normalizing this amount of data would require many-to-one relationships (many people live in one particular region, many people work in one particular industry, many people went to that school, many people have this interest), which does not fit nicely into the document model. In relational databases, it’s normal to refer to rows in other tables by ID, because joins are easy. In document databases, joins are not needed for one-to-many tree structures, and support for joins is often weak. If the database itself does not support joins, you will have to emulate a join in the application code by making multiple queries to the database. In this case, the lists of regions and industries are probably small and slow-changing enough that the application can simply keep them in memory. But nevertheless, the work of making the join is shifted from the database to the application code within a JSON-document storage structure. Moreover, even if the initial version of an application fits well in a join-free document model, data has a tendency of becoming more interconnected as features are added to applications.
Nested records
JSON premised Document databases have reverted back to the hierarchical model in one aspect: storing nested records (one-to-many relationships, like positions, education, and contact_info in a CV for example), within their parent record rather than in a separate table. However, when it comes to representing many-to-one and many-to-many relationships, relational and document databases are not fundamentally different: in both cases, the related item is referenced by a unique identifier, which is called a foreign key in the relational model and a document reference in the document model. That identifier is resolved at read time by using a join or follow-up queries. To date, document databases have not followed the path of CODASYL.
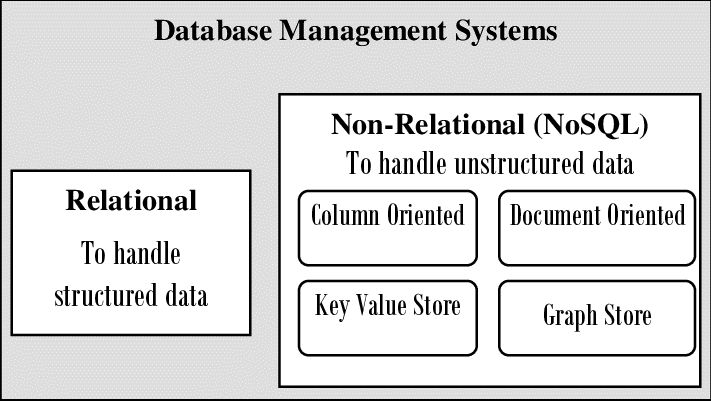
Relational Versus Document Databases
There are some differences to consider when comparing relational databases to document databases, including their fault-tolerance properties and handling of concurrency. However, an often overlooked key difference is the data model.
The main arguments in favour of the document data model are:
- schema flexibility,
- better performance due to locality,
- and that for some applications it is closer to the data structures used by the application.
The relational model would counter the above by providing better support for joins, and many-to-one and many-to-many relationships. Which data model leads to simpler application code?
If the data in your application has a document-like structure (i.e., a tree of one-to-many relationships, where typically the entire tree is loaded at once), then it’s probably a good idea to use a document model. The relational technique of shredding — splitting a document-like structure into multiple tables (like positions, education, and contact_info) — can lead to cumbersome schemas and unnecessarily complicated application code.
Nevertheless, the document model has limitations. For example, you cannot refer directly to a nested item within a document, but instead you need to say something like “the second item in the list of positions for user 251” (much like an access path in the hierarchical model). However, as long as documents are not too deeply nested, that is not usually a problem.
The poor support for joins in document databases may or may not be a problem, depending on the application. For example, many-to-many relationships may never be needed in an analytics application that uses a document database to record which events occurred at which time. However, if your application does use many-to-many relationships, the document model becomes less appealing. It’s possible to reduce the need for joins by denormalizing, but then the application code needs to do additional work to keep the denormalized data consistent. Joins can be emulated in application code by making multiple requests to the database, but that also moves complexity into the application code.
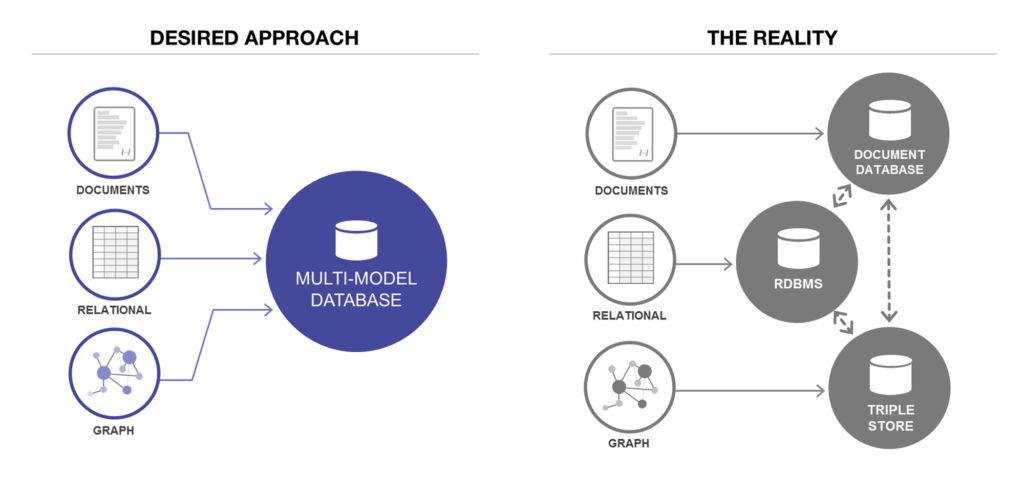
Convergence
Most relational database systems support XML. This includes functions to make local modifications to XML documents and the ability to index and query inside XML documents, which allows applications to use data models very similar to what they would do when using a document database. PostgreSQL since version 9.3, MySQL since version 5.7, and IBM DB2 since version 10.5, also have a similar level of support for JSON documents. Given the popularity of JSON for web APIs, it is likely that other relational databases will follow in their footsteps and add JSON support.
On the document database side, RethinkDB supports relational-like joins in its query language, and some MongoDB drivers automatically resolve document references (effectively performing a client-side join, although this is likely to be slower than a join performed in the database since it requires additional network round-trips and is less optimized). It seems that relational and document databases are becoming more similar over time, and that is a good thing: the data models complement each other. If a database is able to handle document-like data and also perform relational queries on it, applications can use the combination of features that best fits their needs. A hybrid of the relational and document models is a good route for databases to take in the future.
Coexistence: NoSQL and SQL will continue to co-exist, with some parts of the models merging to form hybrid database systems over time. NoSQL is often mistakenly assumed to be ‘better’ than the SQL. This depends entirely on the type of data, documents and information that is being stored and accessed. More likely, NoSQL has a role to play in the architecture, especially with unstructured data, and data that grows and expands and demands scalable storage.