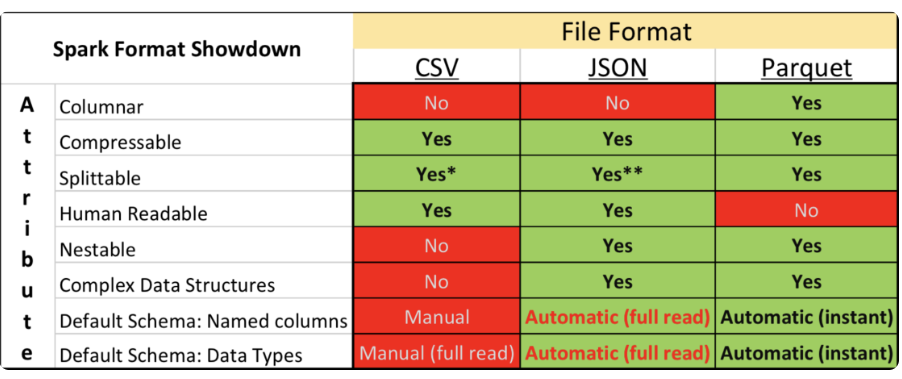
Parquet is a file format standard used in many enterprises. It allows the standardisation of files and provides a common framework for queries and storage. Parquet is a hybrid columnar-row format. The hybrid format combines the best of both worlds.
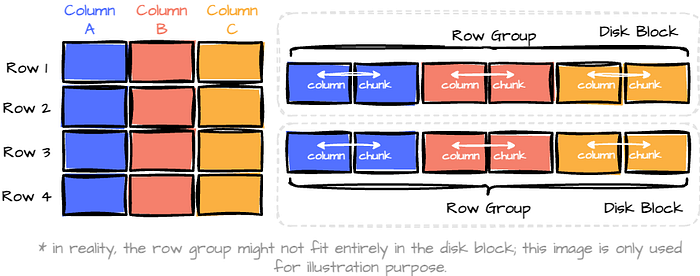
The format groups data into “row groups,” each containing a subset of rows. (horizontal partition.) Within each row group, data for each column is called a “column chunk.” (vertical partition) In the row group, these chunks are guaranteed to be stored contiguously on disk.
A Parquet file is composed of:
- Row Groups: Each row group contains a subset of the rows in the dataset. Data is organized into columns within each row group, each stored in a column chunk.
- Column Chunk: A chunk is the data for a particular column in the row group.
- Pages: Column chunk is further divided into pages. A page is the smallest data unit in Parquet. There are several types of pages, including data pages (which contain the actual data), dictionary pages (which contain dictionary-encoded values), and index pages (used for faster data lookup).
Parquet is a self-described file format that contains all the information needed for the application that consumes the file. This allows the software to efficiently understand and process the file without requiring external information. Thus, the metadata is the crucial part of Parquet:
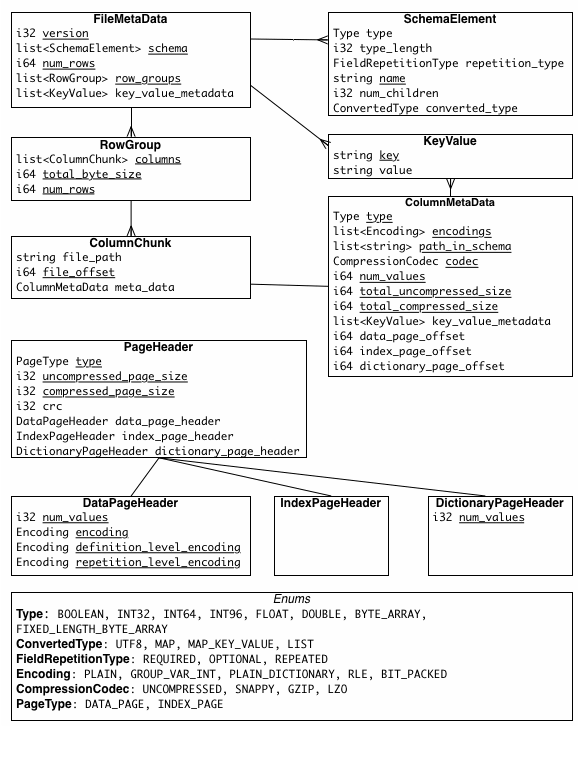
- Magic number: The magic number is a specific sequence of bytes (
PAR1) located at the beginning and end of the file. The number is used to verify if it is a valid Parquet file. - FileMetadata: Parquet stores FileMetadata in the footer of the file. This metadata provides information like the number of rows, data schema, and row group metadata. Essentially, each row group metadata contains information about its column chunks (ColumnMetadata), such as the encoding and compression scheme, the uncompress/compress size, the page offset, the number of values, and the min/max value of the column chunk. When navigating the Parquet file, the application can use information in this metadata to limit the data scan; it can prune unnecessary row groups based on the filter or choose to read only required columns.
- PageHeader: The page header metadata is stored with the page data and includes information such as value encoding, definition encoding, and repetition encoding. In addition to the data values, Parquet also stores definition and repetition levels to handle nested data. The application uses the page header to read and decode the data.
==End