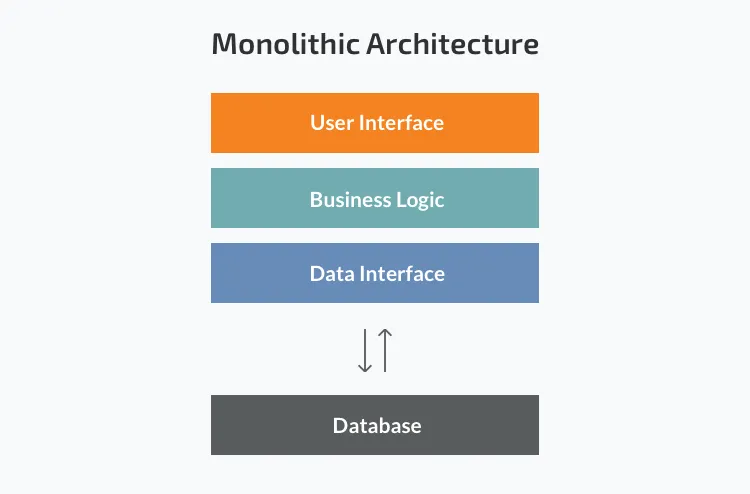
Monolithic applications are designed to handle multiple related tasks. They’re typically complex applications that encompass several tightly coupled functions. You don’t need to, nor will you, ‘containerise’ every single application. Depending on the use cases, scaling-needed and end user demands, monoliths can be practical and relevant deployments.
An example of a monolithic application might be an application serving an internet retail system. It might contain a web server, a load balancer, a catalogue service that services up product images, an ordering system, a payment function, and a shipping component. Internet facing retail applications are good candidates to refactor and containerise due to the potential need of scaling up and down during different points in time.
Given their broad scope, monolithic applications tend to have very large and complicated codebases, not usually that thoroughly documented. Making a small change in a single function can require compiling and testing the entire platform, which goes against an agile delivery model (small, cross functional teams, using iterative programming and testing, to deliver small incremental improvements in short periods usually 2 to 3 weeks).
The Advantages of using monoliths
Monolithic applications are a natural way for an application to be deployed. Most applications start out with a single objective or a small number of related objectives. Over time, features are added to the application to support business needs. The most obvious place to put new functionality is in the existing application. There are several reasons for this:
Communication costs
The cost of communicating components is near zero when the code is in the same application stack. Meaning, developers do not need to think about, or code around, things like networks and availability.
Reusability
If the technical and business requirements and logic are similar, code from existing applications can be reused when building new applications or adding functionality.
Effort
Starting new applications has always involved significant effort. You must create a new artifact with all the configuration, all the build scripting, and tooling, and an entirely new set of hardware and network configuration (sometimes, a herculean effort). To make it more complex, code reuse is now more complicated across projects.
Monolithic applications provide teams with a single source code tree to work from. All changes accessible by any part of the application, allowing for single teams to work closely on the application. In server-side applications, monoliths have been, and continue to be, the standard for the last 20 years.
Problems with monoliths
Fault tolerance
Monolithic applications have high module interdependency as they are tightly coupled. The different modules utilize functionality in such an intro module manner that even a single module failure brings the system down due to a cascading effect.
Scaling
Scaling is one of the biggest challenges that any business faces while trying to cater to an increased user base. Scaling can include different access points and applications for the same system, including full clients, mobile, and browser. Data synchronisation is complicated with different entry points to the back-end data.
Scalability
Scaling up or down is the capability of a system/program to handle the growth of work better. This is the ability of a system/program to scale or expand and contract. The scalability of a system is its capability to handle an increasing/increased load of work. There are two main strategies or types of scalability.
Modularity
In respect to our monolithic application, where we may have an Order module, a change in the module Orders affects the module Stock and so on. It is the absence of modularity that has resulted in such a condition. This also means that we can’t reuse the functionality of a module within another module. The code is not decomposed into structured pieces, which could be reused to save time and effort. There is no segregation within the code modules, and hence, no common code is available.
Big database
Our current application has a mammoth database containing a single schema with plenty of indexes. This structure poses an issue when it comes down to fine-tuning the performance. Whenever a deployment is planned, the team will have to look closely at every database change. This again is a time-consuming exercise, and many times would turn out to be even more complex than the build and deployment exercise itself.
Scaling a Monolith
Vertical Scaling
Usually, the obvious solution for scaling a monolith is to scale-up (vertical). This generally means increasing resources. Increasing CPU, Memory, Network, Storage, etc, for higher performance, allows you to perform more work and handle more load.
Horizontal Scaling
Scale-out (horizontal) scaling is distributing the workload over many resources. Loosely coupled systems allow you to distribute the system over different resources and provide better availability. Monoliths cannot be horizontally scaled, unless they are broken down into modules.
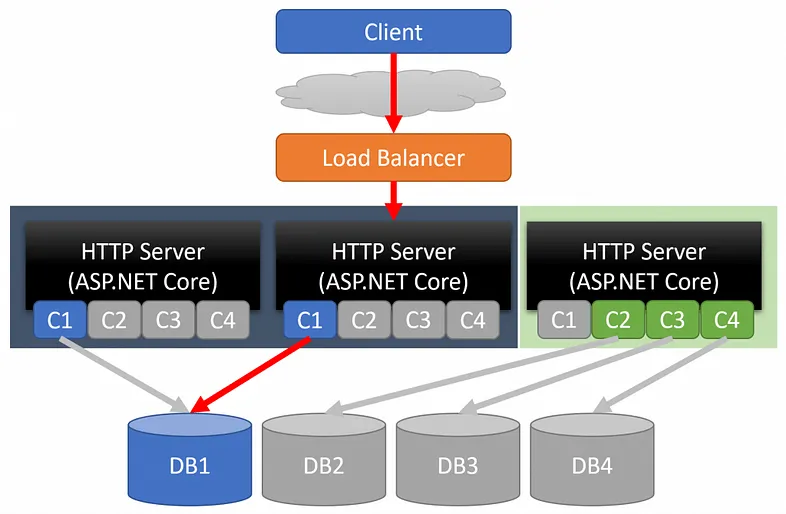
Using load balancers
Requests are handled by a load balancer, which then distributes the requests to the application. There are a variety of ways a load balancer distributes requests, the most common being Round Robin.
With a loosely coupled monolith, because we have very defined boundaries, this allows you to scale even further. You can start scaling the individual boundaries.
Split the codebase into several boundaries
However, we can create load balancing rules to create groups of servers that will only handle requests for a specific boundary. These are often called Target Groups. With well-defined boundaries, you can decide how to scale and route traffic with a load balancer to a target-group that handles that boundary. Although each server has all the code in our monolith, it is really only using the boundary that it’s handling. All other boundaries are basically dead code.
Database
The database can also become a bottleneck in a monolith. But just as you can scale by the boundary on the application/hosting layer, you can also make these same types of scaling decisions at the database layer of the topology. If one boundary has to handle more load, you could scale each database vertically differently. In the example above, DB1 might have more resources (CPU, Memory, etc) than the others. Or you may choose to scale horizontally at the database level by adding read replicas or a cluster.
Conclusion
Monoliths serve a valid architecture purpose. Their usage will mostly depend on how much you need to scale. If your user base is the same every day, every month, every year, and the system load is well-known and does not vary that much, than using a monolith is a valid and rational decision.
Scaling a Monolith Horizontally (code opinion)
Are monolithic software applications doomed for extinction?
Monolithic applications (Microsoft)