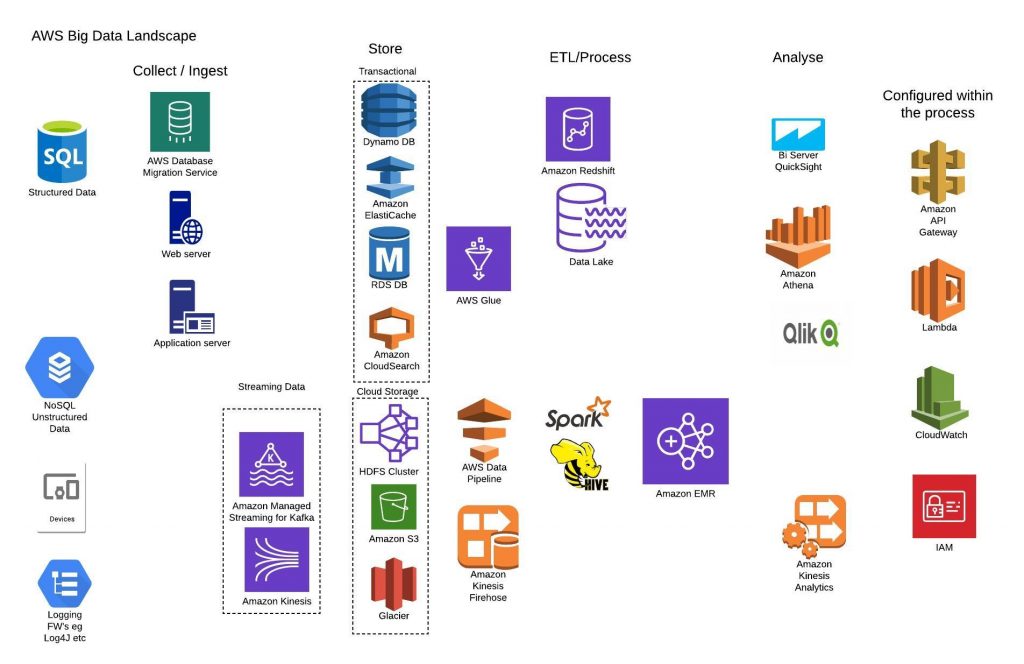
Migrating ‘ Big Data’ pipelines and data processes to AWS will allow organizations to:
- Scale Seamlessly: AWS services like EMR (to replace Hadoop), S3, and Glue offer dynamic scalability to meet fluctuating data loads.
- Reduce Costs: The pay-as-you-go model eliminates the need for upfront infrastructure investments.
- Enhance Performance: Cloud-native tools optimize data processing and storage.
- Enable Advanced Analytics: AWS’s ecosystem integrates seamlessly with AI and ML tools, opening new possibilities for data-driven insights.
Challenges in Migrating Big Data Pipelines
1. Data Volume and Complexity
Big data pipelines often deal with terabytes or even petabytes of data. Moving such massive datasets while maintaining integrity can be daunting.
Solution: Use AWS Snowball for massive >1 PB size physical data transfer or S3 Transfer Acceleration for faster uploads. Implement checksums and data validation to ensure integrity during and after migration. AWS DataSync, AWS Data Migration Service should also be used for volumes <1 PB.
2. Rebuilding Data Workflows
Existing workflows built on on-premises platforms like Hadoop or Spark need to be re-engineered to leverage AWS’s serverless architecture.
Solution: Leverage AWS Glue for ETL processes and rewrite workflows to align with Glue’s serverless model. Utilize services like Lambda for event-driven data processing.
3. Application Downtime
Migration can disrupt ongoing data processing and analysis, potentially impacting business operations.
Solution: Plan migrations in phases and prioritize non-critical datasets initially. Implement hybrid solutions to run workloads simultaneously on-premises and in the cloud during the transition.
4. Security and Compliance
Ensuring data security and compliance with regulations like GDPR and HIPAA is critical during migration.
Solution: Use AWS Identity and Access Management (IAM) for secure access control. Encrypt data at rest with AWS Key Management Service (KMS) and in transit with SSL/TLS.
5. Cost Management
Without proper planning, costs can spiral out of control, especially when transferring and processing large volumes of data.
Solution: Use AWS Cost Explorer and Trusted Advisor to monitor and optimize expenditures. Configure lifecycle policies in S3 to automatically transition data to lower-cost storage tiers.
6. Team Readiness and Skills Gap
Teams accustomed to traditional data platforms may lack the skills required to manage AWS services effectively.
Solution: Invest in training programs for AWS tools and services. Provide hands-on workshops to familiarize teams with cloud-native paradigms.
Best Practices for a Smooth Migration
- Assess and Plan Thoroughly: Conduct a comprehensive assessment of current pipelines, dependencies, and business requirements.
- Leverage AWS Services:
- Use AWS S3 for scalable storage.
- Employ AWS EMR for distributed big data processing.
- Implement AWS Glue for seamless ETL workflows.
- Automate Wherever Possible: Use AWS Step Functions and CloudFormation to automate deployment and workflows.
- Test Rigorously: Validate data integrity, workflow functionality, and performance in a staging environment before going live.
- Monitor Continuously: Use AWS CloudWatch for real-time monitoring and logging to identify and resolve issues promptly.
Real-World Benefits of Migrating to AWS
Organizations that successfully migrate big data pipelines to AWS experience:
- Faster Data Processing: Cloud-native tools reduce latency and enhance throughput.
- Cost Savings: Dynamic scaling minimizes resource wastage.
- Improved Insights: Seamless integration with AWS analytics and AI services unlocks advanced insights.
- Enhanced Collaboration: Cloud-based platforms enable better collaboration across distributed teams.