Kong
Kong API Gateway sits in front of the backend API services. The gateway forwards client requests to those services. Kong is the first point that the client or requesting application will hit. Kong can transform and route the requests and responses, based on the gateway’s configuration and policies. This means that it is possible to manipulate requests and responses by adding, appending, or removing headers dynamically, and routing them to the proper service.
Kong has an abstraction layer which provides additional features as well with plugins including authentication, rate limiting, caching, logging, botdetection, IP restriction and CORS and many more. These plugins allow the client to focus on business logic and not lower-level application and infrastructure logging or integration.
Kong usually runs as a docker container on a Linux distribution in the Cloud or on -premises. It is sometimes used as a Kubernetes ingress controller.
Architecture
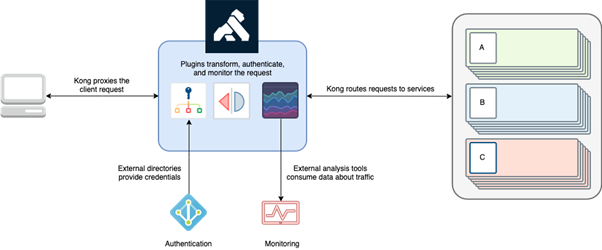
(source Kong Docs)
Kong is built on top of Nginx and by using its own admin API, it configures the nginx server to provide proxying for backend services.
Kong uses OpenResty which is an enhanced version of nginx that includes a Lua-nginx-module. Kong is distributed along with OpenResty to leverage its Lua scripting capability to configure and extend nginx.
Kong accepts the reverse proxying directives via its own admin API over http/s, translates them to an nginx configuration using Lua scripting language and builds a gateway platform for micro service backends.
Admin API
The Admin API is accessible on TCP/8001(http) and TCP/8444(https) ports. As a security best practice, Admin API ports are for internal use and should be firewalled.
Proxying
Kong listens on TCP/8001(http) and 8443(https) ports to receive end-user requests and according the configuration you define, forwards to your endpoints. Those ports are publicly facing services that must allow external connections.
Datastore
Kong uses an external database to store configurations data. Pass the configuration directives to the admin API and Kong stores them in its datastore. Multiple Kong servers can use a central database. Supported datastores are Cassandra and PostgreSQL. You can also use Aurora Postgres on AWS (DBaaS).
Cache and configuration
To avoid the DB becoming a bottleneck, Kong maintains a cache to hold the configuration data in the node’s memory. When there is a call to the admin API to configure Kong, the configuration data is written to the external datastore, then pulled from the external DB and written to the node’s memory as cache; and the configuration is applied. At this point there is no need for a database roundtrip anymore while proxying requests. If you do any configuration change, Kong invalidates the cache and pulls the new configuration to cache it again.
DB-less Mode and Declarative Configuration
There is another option called DB-less mode. In this mode the configuration directives is declared as a JSON or YAML formatted configuration file, thus Kong reads this file to get configuration directives and write it to node’s memory.
With this mode, you can manage Kong by using a CI/CD tool. Since, configuration directives are stored in a static file, you can keep it in a git repository and distribute to multiple Kong nodes. In this mode the Admin API is read-only, because the only way to configure Kong is using a declarative configuration file. In other words, you can’t pass any configuration directives to the admin API over REST API.
Clustering
If the gateway cluster fails the application is unreachable, so the gateway must redundant and scalable. Kong uses the central DB to create multiple Kong nodes and a cluster.
Overview: (from Kong Docs)
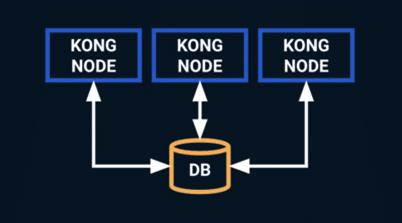
Kong is not a load balancer. You must deploy a load-balancer in front of the Kong cluster to distribute traffic. If there is a need to handle more incoming requests, one can easily add more nodes horizontally by installing Kong on the new nodes and pointing them to the central datastore.
It is straightforward to track Kong cluster resources utilization (by collecting metrics via plugins) and decide to scale up or down automatically. Kong installation and initial configuration is a quite straightforward process which can be easily automated using Terraform or similar IaC.
Hybrid Mode Clustering – Control and Data Planes
Kong nodes are dependent on the central datastore, but there also a Hybrid mode to build a Kong cluster. In this mode, Kong nodes are separated into two roles called Control Plane Nodes (CP) and Data Plane Nodes (DP).
CP nodes provide the Admin API and are the only components that interact with the central datastore, and DP nodes (which handle incoming requests), must fetch their configuration from a CP node.
Modes: (Kong Docs)
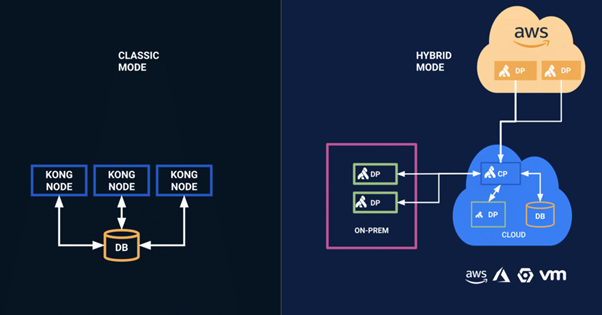
See https://docs.konghq.com/2.0.x/hybrid-mode/
Features
Kong has many plugins found on the Kong Plugin Hub.
Authentication Mechanism
This provides authentication mechanisms to the backend services; and it’s possible to use different mechanism for each service. For example, while service-A is using basic authentication, service-B only accepts request with JWT token. Supported modes include:
- Basic Auth
- LDAP integration
- OAuth 2 integration
- Key based auth
- HMAC auth
- JWT tokens
Security
Various out of the box plugins exist including encryption, integration, CORS, IP restrictions, BOT detection etc.
Traffic Control
Traffic control plugins are useful to reduce load on the backend services. A Proxy cache plugin, for example, caches mostly responded request in Kong nodes’ memory. By caching frequently requested responses which run heavy SQL queries on the backend, the cache-proxy will reduce load on the DB and related services.
Other plugins are:
- Rate limiting
- ACL (defines, who can access the services)
- Request body size limiting
- Request terminating (Terminates certain request with a specific status code.)
Analytics & Monitoring
The decoupled nature of microservices increases the complication of Observability (monitoring and logging). Kong is an API gateway which sits between clients and services. As an intermediary it contains many important metrics for both infrastructure and application logging and tracing. Datadog is commonly used for metrics and dashboarding and Splunk is used for activity and infrastructure logging and analysis including security.
Logging
Logs (Splunk, fluentd, Data Dog or similar) are collected, parsed, stored and visualized (Dashboards). Kong has plugins to ship logs to remote logging systems in various ways to make them to be processed!
- Syslog
- HTTP Log
- StatsD
- TCP/UDP Log
Transformation
Kong also provides plugins which can be used to manipulate requests or responses dynamically in real-time. These allow the user or admin to add, remove or replace a header, body or query string of the requests or responses. There is also a ‘Correlation ID’ plugin, which injects unique ID to requests or responses in order to track http traffic flow.
- Request & Response Transformer
- Correlation ID
- gRPC Web
- Inspur Request & Response Transformer
Installation & Configuration
Example setup (simple) to create, install, monitor.
Linux Distribution eg. RHEL, on 3 separate instances to build a cluster.
Each component runs on top of Docker.
1-Datastore eg. Postgres SQL Docker container on one of the RHEL instances. (For production this must be made redundant, HA by using a replica cluster). IP address example: 10.10.10.11
2-Kong Nodes, use the other 2 instances and deploy Kong Nodes as Docker containers (in prod you don’t run multiple Kong nodes on a single instance). Kong Node 01: 10.10.10.21 and Kong Node 02: 10.10.22.
Step 1 — Prepare Nodes
Deploy Docker onto the Nodes.
Step 2 — Deploy PostgreSQL Container on Datastore Node
Connect your Kong-datastore instance and connect (DB named Kong is created, connect with kong/kong credentials).
Step 3 — Prepare Kong Database
Next, switch to one of the Kong node instances and run a bootstrap command to make initial configuration on the DB such as creating schema etc by pointing to the Postgres host via Kong_PG_Host parameter.
Step 4 — Starting Kong Nodes
Start the Kong container on every node via the command set.
Variables:
KONG_DATABASE and KONG_PG_* Defines which datastore Kong node will connect to.
KONG_{PROXY|ADMIN}_{ACCESS|ERROR}_LOG As a common containerized application approach, this parameters redirects admin API and proxy http logs to stdout and stderr by its category.
KONG_{ADMIN|PROXY}_LISTEN
Configures addresses and ports on which the proxy and admin API should listen for HTTP/HTTPS traffic.
(TCP/8001 for http and TCP/8444for https traffic and proxy server will listen to TCP/8000 for http and TCP/8443for https.)
Backlog=N parameter, sets the maximum length for the queue of pending TCP connections. This number should not be too small in order to prevent clients seeing “Connection refused” error connecting to a busy Kong node.
There is also a net.core.somaxconn parameter, and this needs to be increased at the same time to match or exceed the backlog number.
Step 5 — Check if Kong Nodes are running
Run the Kong nodes with admin API via TCP/8001 or TCP/8444 on localhost.
Use a curl command to call the local hosts. If live, a JSON output is returned that shows the configuration.
Securing Kong Admin API
In order to expose the admin API securely, adding fine-grained access control measures such as authentication and authorization is mandatory. This can be done manually or with the Kong plugins.
==END