AWS Glue is a meta data catalogue service with Extract-Transform-Load logic. The Glue catalogue is based on Hive and is a MySQL DB and a Java front end. Glue ‘jobs’ or ETL logic is based on python and spark code or scripts. Glue jobs can run in AWS or reach back into on premise data stores. Glue is a managed service, i.e. AWS manages the infrastructure.
Glue’s simplified architecture: Data Source; Glue crawler; Glue Database; Glue Table and Data source to Glue ETL job; S3 and updating the catalogue.
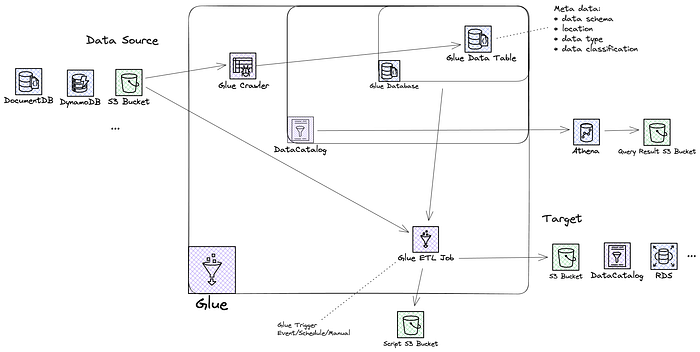
1. Data Source:
- Databases, data lakes, or even streaming data.
- AWS Glue works seamlessly with various data sources, ensuring compatibility and easy access to your data.
2. Glue Crawler:
- Code or an ‘agent’ which automatically discovers and catalogs data from various sources.
- Glue Crawler extracts metadata and creates a data catalog, making it easy to search and query the data.
3. Glue Catalog:
- The Glue Catalog acts as a centralized repository for all your data assets, including databases and tables.
- It organizes your data in a logical structure, making it accessible and manageable for analysis.
4. Glue ETL Jobs:
- ETL (Extract, Transform, Load) is the process of moving data from one place to another while transforming it along the way.
- With Glue ETL jobs, you can easily extract data from the source, apply transformations, and load it into a target destination, such as Amazon S3 or Redshift.
5. Analytics with Athena and Redshift:
- Athena allows you to query data directly from your S3 data lake using standard SQL queries. It’s perfect for ad-hoc analysis and exploration.
- Redshift, on the other hand, is a fully managed data warehouse service that allows you to run complex SQL queries at lightning speed. It’s ideal for large-scale analytics and reporting.

AWS Glue simplifies the complex process of data integration and analysis, and has powerful features like data discovery, ETL, and analytics. The Glue catalogue is fundamental to understand, manage and use your data and data products properly.