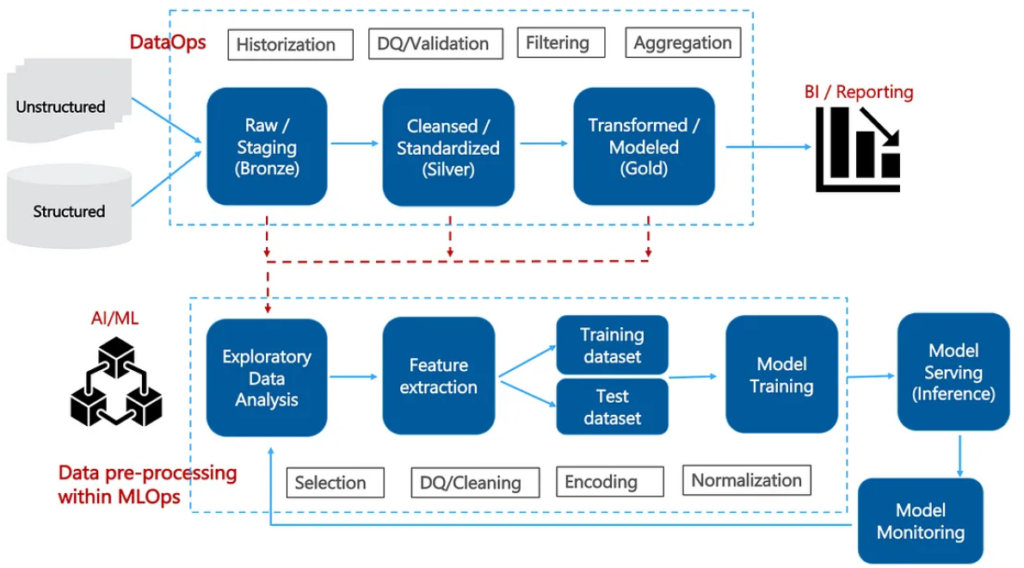
The data (pre-)processing part of MLOps focuses on moving data from the source to ML model, without necessarily including how the model executes on the data itself. This commonly includes a series of transformations that support a learning algorithm. For example, a data scientist may choose to build a linear regression pipeline or an exploratory factor analysis pipeline to support ML models.
Note: ML training and validation requires performing more complex functions than supported by most ETL tools. This is often the case in complex data processing, aggregation and regression. The recommended approach here is to complement the data processing strategy with directed acyclic graph (DAG) flows.
In contrast to the more linear data flow in case of BI, DAG flows support scalable directed graphs for data routing, statistical transformation and system logic. Tools like Apache Airflow support the authoring, management and maintenance associated with DAG flows, which can then be programmatically authored to integrate with ETL pipelines.
Needless to say, this results in redundancy and a fragmentation of the DataOps and MLOps pipelines. It seems fair to say that DataOps today relates more to BI/structured analytics, and MLOps addresses the full ML pipeline with data (pre-)processing embedded within it.
Data platform vendors have started working towards this, and we have seen some initial offerings to resolve this. Snowflake provides Snowpark Python API that allows ML models to be trained and deployed within Snowflake, with Snowpark allowing data scientists to use Python (rather than writing code in SQL).
Google cloud platform (GCP) provides BigQuery ML, a GCP tool that allows ML models to be trained purely using SQL within GCP’s data warehouse environment. Similarly, AWS Redshift Data API makes it easy for any application written in Python to interact with Redshift. This allows a SageMaker notebook to connect to the Redshift cluster and run Data API commands in Python. The in-place analysis provides an effective way to pull data directly into a notebook from a data warehouse in AWS.