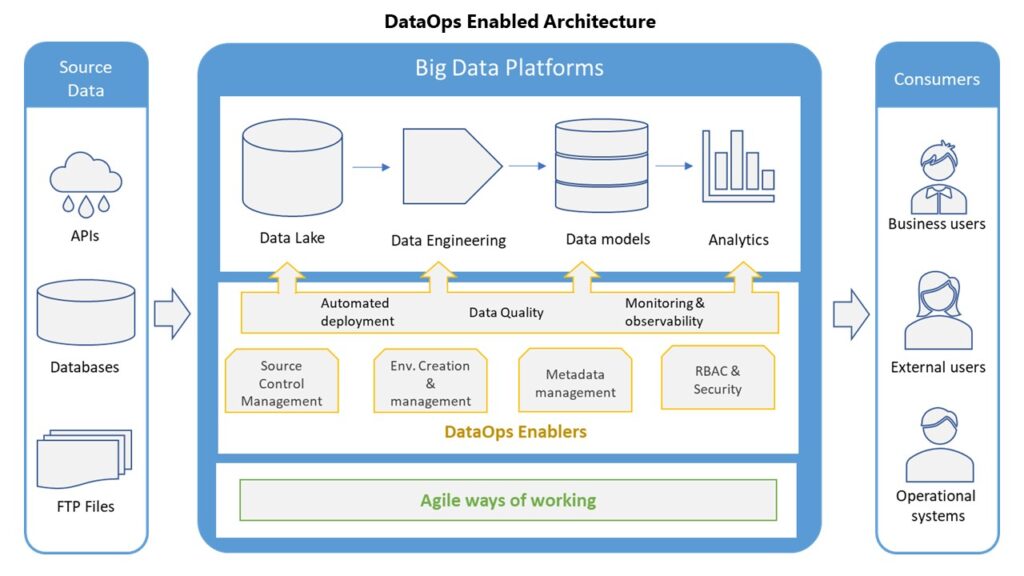
In essence Data Operations is based on DevSecOps or DevOps and applies these same ideas to the life cycle of data management. DataOps advocates for agility, namely standardisation, automation (which needs to be defined), cross functional team-collaboration, and continuous delivery and improvement. A platform which provides functionality to achieve this by abstracting away the underlying complexity will allow data to move from source to end user consumption quickly, accelerating the life cycle of data management and aligning engineers, ‘data scientists’, regulators, the business and other stakeholders.
- Data Orchestration
- A DataOps platform provides or integrates the tools and processes to orchestrate the flow of data from heterogenous sources to usage. This includes diverse systems of data ingestion, transformation and consumption compute.
- Data Quality and Governance
- A DataOps platform will only be useful if the data has integrity, lineage, approval and there are governance processes within the operational model which guarantees the reliability of data throughout in its lifecycle.
- Scalability and Agility
- A DataOps platform framework must allow the VLEs to scale data operations to a Data Lake, as data ingestion volumes grow, and business requirements change. The ability to quickly adapt to new data sources and technologies is crucial in a dynamic environment.
- Collaboration and Communication
- DataOps fosters a culture of collaboration between data teams, breaking down silos and promoting shared ownership of data processes. This is essential for effective troubleshooting, optimization, and innovation.
Components
The core components of Data Ops include the following which is what the author sees and uses in real life within VLEs.
- Data Pipelines: By pipeline we mean an automated way to get data from a server, to S3 or the Data Lake. This usually includes formatting the data into Parquet or Iceberg. It includes several steps or configuration processes to extract, transform and load the data (ETL).
- Data Orchestration: The coordination and management of the data pipelines, to allow an efficient and controlled execution. AWS offers a pipeline for example to orchestrate data in its journey.
- Data Quality: The deployment of tools (some 3rd party), and even manual processes to check the quality of data. This would include SIT, Regression and sanity checks.
- Data Governance: A key element in all of this is to build data policies, data tagging, attribute tagging, and pipelines around table management which are approved and known within the VLE.
- Data Visualization and Analytics: This includes compute and end user tools and systems which consume, manipulate and report on data. Usually this entails the creation of ‘data product’s or the self-standing data sets used by ‘actors’ within the VLE. Data products can be summarised quite easily in a diagram or two, the complexity is how to build them to the defined standard. Examples could include Databricks (compute) or PowerBI (management reporting).
- Monitoring and Observability: Telemetry and reporting will use both AWS and 3rd party products and services; telemetry is built into the entire Data Operations flow.