Data Operations
‘DataOps’ has been inspired by the Agile-premised ‘Development Operations’ model. The ‘DevOps’ model which usually includes security (DevSecOps), proposes a technology driven, and collaborative approach to designing, building and deploying systems and applications. The author has been involved in DevOps for more than 15 years in some capacity as Team Lead, Scrum Lead, Enterprise or Solution Architect or a Tech SME. We can apply many of these same ideas to the world of data management. When you view the flows of data, it does imitate a DevOps pattern.
Figure 1: Flows and technology complexity
(ignore the tooling or platforms for now)
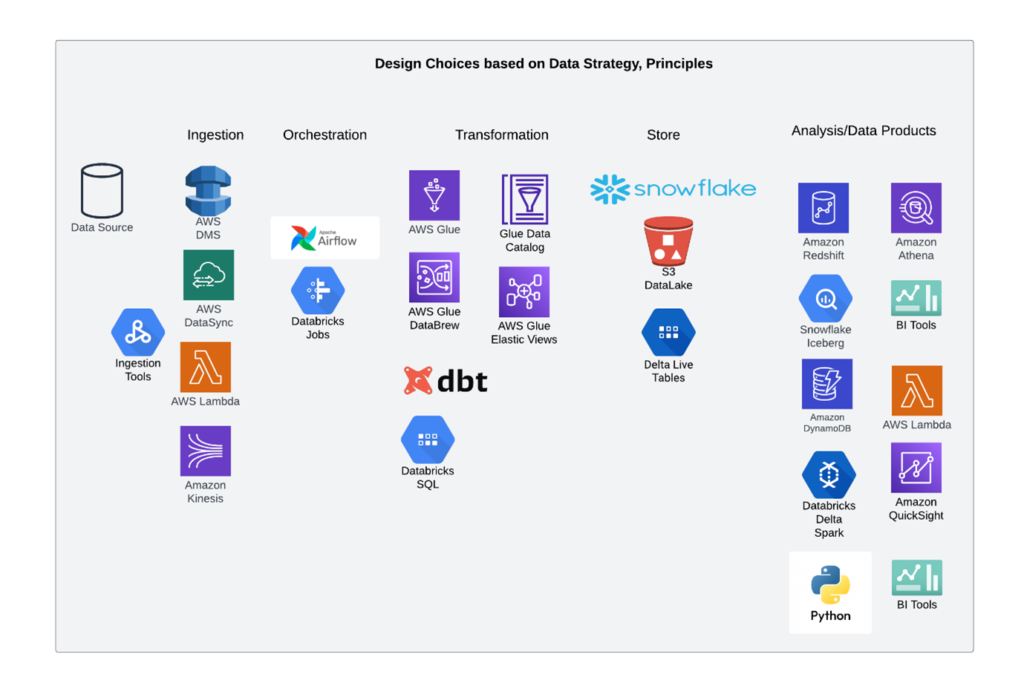
There is a defined life cycle within DataOps from having a data source (database and application) to an end user with a tool, using the source data in some defined and usually prescriptive manner. The challenges are the same that we see with DevOps namely, skills, resources, automation, continuous integration, and delivery (CI/CD), and observability (monitoring, logging, security). A DataOps ‘platform’ would streamline the entire data lifecycle, from ingestion to consumption. It would force collaboration between data engineers, data scientists, and other stakeholders, breaking down silos and promoting shared ownership of data processes. It would reduce headcount, manual interventions, data quality issues, and greatly reduce time from data source to data product.
Agile
‘DevOps’ is built around Agile. The author has developed an Agile application framework in AWS to manage the life-cycle maturity of Agile. Agile is difficult and means different things to every company. There is no single ‘right way’ to implement Agile in the author’s opinion. When building systems in the 1990s the author employed ‘Agile’ methods before the methodology was named as such. The reason is simple – IT engineers and SMEs do not understand the Business lexicon or domain language.
The same is true going the other way. The only practical method of building complex systems is to embed the ‘Business’, its owners, SMEs and budget-stakeholders, within the Agile-Engineering team. The same will be true for DataOps. More practically the author deals with Agile teams and Data Operations every day and can see where standards and proper alignment would greatly benefit Data productivity.
Challenges
We should list the key challenges facing VLEs with their Data management.
- Massive heterogenous IT complexity
- Different systems, databases, operating systems, applications, code, logic, ETL (extract transform load), ELT (extract load then transform), APIs and system interfaces. Data Lake and DataOps integration with ‘legacy’ systems is an obvious challenge.
- Data formats, types
- A wide variety of data types exist (structured and unstructured), along with differing formats. Building a framework to allow the ingestion of this data complexity is not an easy task.
- Regulatory pressures
- Regulatory demands can be near real-time, demanding complex historical data analysis and proofs, a ‘Data Lake’ is an absolute priority for Finance firms and ‘hydrating’ this lake with Data Ops just to satisfy regulatory requirements a massive driver.
- Cloud native drivers
- For many reasons data management is more easily accomplished with the cloud-hyperscaler platforms than on premises, there are many drivers to move data and related applications to the ‘cloud’, the enduring questions are how to do this at velocity and with control
- Scalability
- Finance firms deal in exabytes of data, meaning that the hyperscaling potential of ‘cloud’ aligns itself nicely with data management, yet most Data Operations lack the inherent scalability in processing or in data management that one would expect in the ‘cloud’
- Real time
- Often ‘real time’ or ‘near real time’ systems need data refreshing and complex pipelines, an area where most DataOps systems fail and where the ‘use cases’ for real time are insufficiently addressed
- SLAs
- Service Level Agreements include the end user SLAs demanded by regulatory agencies such as the FCA in the UK, system SLAs internally, SLAs externally to 3rd parties and various demands from governmental agencies such as GDPR. Managing data across the SLA landscape is a real challenge if we look at structured and unstructured data.
- Security
- Security is usually a ‘blocker’ on most projects especially within Finance. This is due to many factors, but one key element is the lack of security pattern automation within a reusable and accepted platform. This means that security review are essentially project based reviews and can hamper Data Operations.
This is not an exhaustive list, but the challenges given above, based on the author’s personal experience manifestly impact data management and in most VLEs are unresolved.