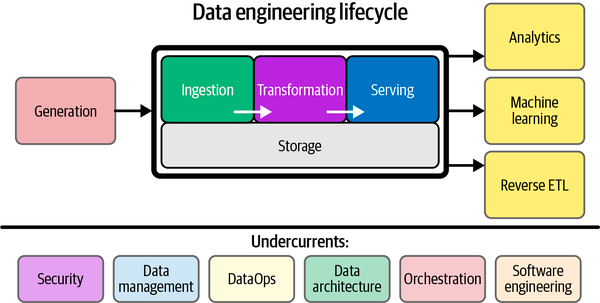
Data Ingestion Challenges
Data ingestion can be complicated. There are usually a variety of data sources, including both SQL and non-SQL based that must connect to the data ingestion process. There is often a landing server on premises, autosys scheduled jobs or similar, pre-processing of the files and then a transfer to AWS landing server or S3. There are differences in files, formats, schemas, structural attributes, methods of acquisition, and the cadence of updates including real time, near real time, batch, daily, and monthly updates. Data duplication, compression, quality are paramount and can be handled at source, within the process, or at the target, or all 3. A key aspect in all of this is automation of course, and not relying on manual interventions or home-made scripts.

AWS Services for Data Ingestion
Application Data with DMS: For data sourced from application databases, data ingestion can be implemented using AWS Database Migration Service (DMS). This service enables the import of data into data lake and employs a Change Data Capture (CDC) system to ensure the continuous and near real-time replication of data modifications.
Real-Time Data with Kinesis: In scenarios demanding real-time data management, Amazon Kinesis is a good fit. Engineered to proficiently handle data streams from diverse origins, including mobile applications, IoT devices, website interactions, and log files, Kinesis undertakes the extensive tasks of capturing, processing, and real-time analysis. This functionality empowers expedited responses, as it consistently enriches the data lake with up-to-date and pertinent information.
Custom and Publicly Accessible Data with AWS Lambda or AWS Batch: For engagements involving custom or publicly accessible data, the optimal choice between AWS Lambda and AWS Batch hinges on the nature and duration of tasks at hand. AWS Lambda is ideally suited for brief tasks, limited to 15 minutes, activated by events like the addition of a new record to a database or the availability of fresh data via a public API. Conversely, AWS Batch caters to extensive tasks demanding prolonged execution times such as the retrieval and processing of substantial datasets from publicly accessible origins.
SaaS Data Integration with Amazon AppFlow: For interactions with SaaS applications such as Salesforce, Slack, or Zendesk, Amazon AppFlow stands as a definitive solution for data ingestion. It orchestrates the seamless transfer of data between these applications and AWS without the need for programming. By means of a few simple configurations, data flows for real-time or scheduled transfers can be established. For example, AppFlow can be used for the periodic synchronization of Salesforce sales data with the data lake or the automated transmission of Zendesk ticket data following any modifications.
Pipeline Orchestration
A multitude of services can be employed for the purpose of orchestrating pipelines. Conventionally, services such as Apache Airflow or mage.ai (a more recent choice) have been utilized. However, these services demand installation on substantial EC2 instances. AWS offers a serverless workflow called Amazon Step Functions.
Stepfunctions is a serverless architecture with a robust integration into the AWS ecosystem. Step Functions help define a sequence of actions or services to be initiated in response to certain events. The construction of pipelines can be facilitated through the utilization of the graphical interface of the Step Functions Studio or through the formulation of pseudocode for its integration into Infrastructure as Code files (using CDK, Terraform, etc.). Stepfunctions is easier and cheaper than using Airflow.
==End