AWS Glue can serve a wide array of data engineering use cases.
Loading Data To The Data Warehouse:
One of Glue’s earliest and most popular use cases is loading semi-structured data from Amazon S3 into Amazon Redshift. By discovering the source data schema, transforming nested or inconsistent formats, and optimizing it for analytics, Glue helps streamline the data loading workflows.
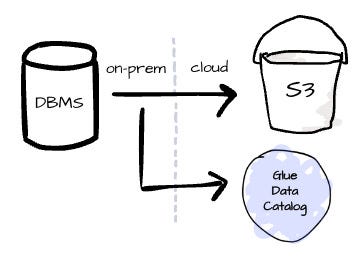
On-prem DBMBS to S3:
Glue helps build and manage the pipelines of copying data from on-prem DBMS on Amazon S3. It simplifies creating table definitions in the Glue Data Catalog, inferring schemas using crawlers, and organizing datasets into efficient, queryable formats like Parquet.
Streaming Data Ingestion:
Glue enables ingestion and transformation of real-time data streams from sources like Amazon Kinesis or Kafka. These pipelines clean and pre-aggregate data before storing it in S3 or loading it into Redshift
Challenges
There are always challenges in moving data, ingestion, storage, transformation, consumption.,
- Inconsistent or Missing Metadata: Semi-structured datasets, like JSON files, often lack schemas, or fields within the same dataset may conflict in type or structure.
- The customer also needs to integrate with many external systems. Diverse sources, such as Amazon S3, DynamoDB, on-premise databases, and relational databases like RDS. Challenges include navigating VPC configurations, subnet management, and differing authentication protocols. The customer needs help configuring these options and reusing them for multiple ETL jobs.
- Apache Spark in Glue scales horizontally, potentially putting more pressure on relational databases or DynamoDB with hot partitions. Customers need a way to throttle ETL jobs and retry strategies to protect source systems while ensuring stable performance.
- Customers need a reliable data processing solution with predictable performance. The data workload can vary for different scenarios. The daily run might process a small amount of data due to incremental data processing, while the backfilling process requires more data.
- Customers also demand a solution to help them with the physical layout and data partition in the object-storage-based data lake. Effective partitioning helps query engines scan fewer files by running unnecessary partitions. File size also plays a crucial role in query performance. Too small files require the engine to execute more operations (fetching/opening/reading/closing), while too big files might limit the parallelism level.
Glue is powerful, but takes training, time and patterns to implement properly.