
AWS Glue was designed based on these principles:
- Provide customers the ability to solve problems when the system can not satisfy their needs. Examples include allowing customers to write code to customize ETL pipelines.
- Glue must support various analytics environments without forcing a single data model, type system, or query language. It should let customers start with their existing data structure and incrementally adopt Glue for new applications and use cases.
- It must reduce time spent managing infrastructure to enhance developer productivity.
Glue contains minor services like the ETL stacks and the Glue Catalog.
ETL stack
It has some core components:
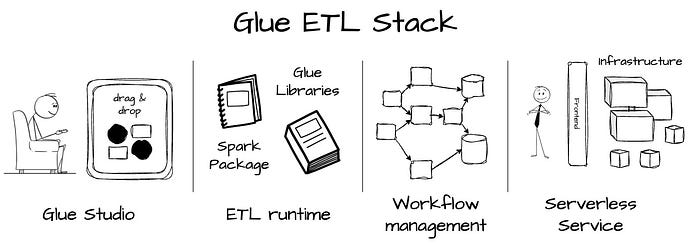
- Glue Studio is a visual interface that automatically generates human-readable Apache Spark scripts.
- AWS Glue ETL runtime includes core Spark packages and Glue-specific libraries. Spark is chosen as the foundation due to its general-purpose nature and familiarity with developers. AWS also extends it with glue-specific libraries to enhance ETL efficiency and resilience, introducing DynamicFrame and specialized transformations to prepare and clean nested semi-structured data more efficiently
- Glue provides an orchestration system to stitch together multiple jobs into a pipeline.
- Glue also lets users run Spark jobs seamlessly. The user only needs to submit the Spark jobs, and this service will take care of everything else. It typically starts in a few seconds and can dynamically scale the resource during job execution.
Glue Data Catalog
Glue also provides a scalable metadata service.
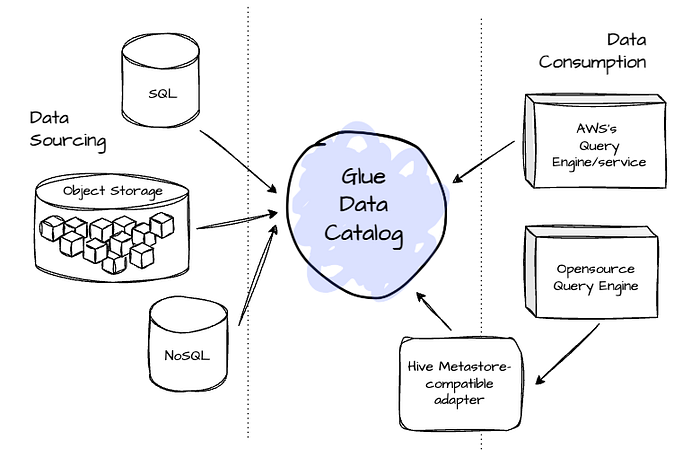
It allows customers to model datasets as databases or tables, supporting data in various stores such as Amazon S3, relational databases, NoSQL stores, and streaming data services.
AWS services like Amazon Athena, Amazon EMR, and Amazon Redshift can query the tables defined in the catalog, and users can leverage an Apache Hive Metastore-compatible adapter for adopting open-source engines like Apache Spark and Presto.