Example project deployment at a Financial Institution.
Creation of a Data Lake with a streaming/real time data ingestion requirement.
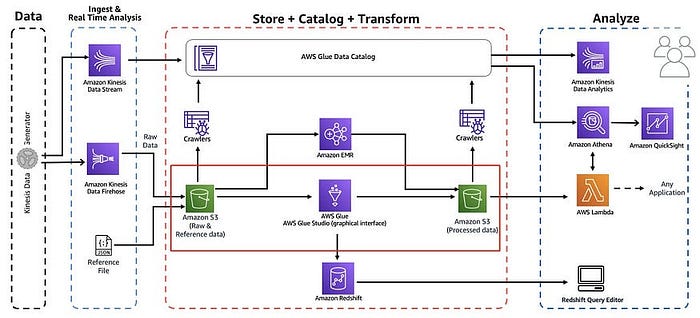
A. Data Ingestion Layer
- AWS Kinesis: Ideal for real-time data streaming, allowing for the ingestion of large volumes of data from various sources such as IoT devices and web applications.
AWS Data Pipeline: Suitable for batch data processing, enabling the scheduling and automation of data movement and transformation tasks.
Handling Real-Time vs. Batch Data Ingestion
- Real-Time Ingestion: Utilize services like Amazon Kinesis Data Streams or AWS IoT Core to capture streaming data efficiently.
Batch Ingestion: Use AWS Data Pipeline or AWS Glue to manage scheduled data loads from on-premises systems or other cloud sources
B. Data Storage Layer
- Amazon S3: Serves as the primary storage solution, offering scalability and durability for raw and processed data.
Amazon Redshift: A powerful data warehousing solution for complex queries and analytics.
Amazon RDS: Useful for structured relational database needs, supporting various database engines.
Implementing Data Partitioning and Indexing Strategies
- Data Partitioning: Organize data in S3 using prefixes to optimize query performance and reduce costs.
Indexing Strategies: Implement indexing in Amazon Redshift to enhance query speed, using sort keys and distribution keys effectively
C. Data Processing Layer
- AWS Glue: Provides serverless ETL capabilities, allowing for easy transformation and loading of data into target storage solutions.
Amazon EMR: Enables big data processing using frameworks like Apache Spark, Hive, and HBase for large-scale data analysis.
Designing ETL Workflows and Data Transformation Processes
- Create ETL workflows using AWS Glue to automate the extraction, transformation, and loading of data from various sources into the storage layer.
Use Amazon EMR for more complex transformations that require distributed processing capabilities
D. Data Access and Analytics Layer
- Amazon Athena: Allows users to perform ad-hoc querying directly on data stored in S3 without needing to load it into a database.
Amazon QuickSight: A business intelligence service that provides interactive dashboards and visualizations based on the ingested data.
Implementing Data Cataloging and Metadata Management
- AWS Glue Data Catalog: Acts as a central repository for metadata about datasets stored in S3, enabling easier discovery and management of data assets.
Ensure proper governance by implementing access controls and auditing capabilities across all layers