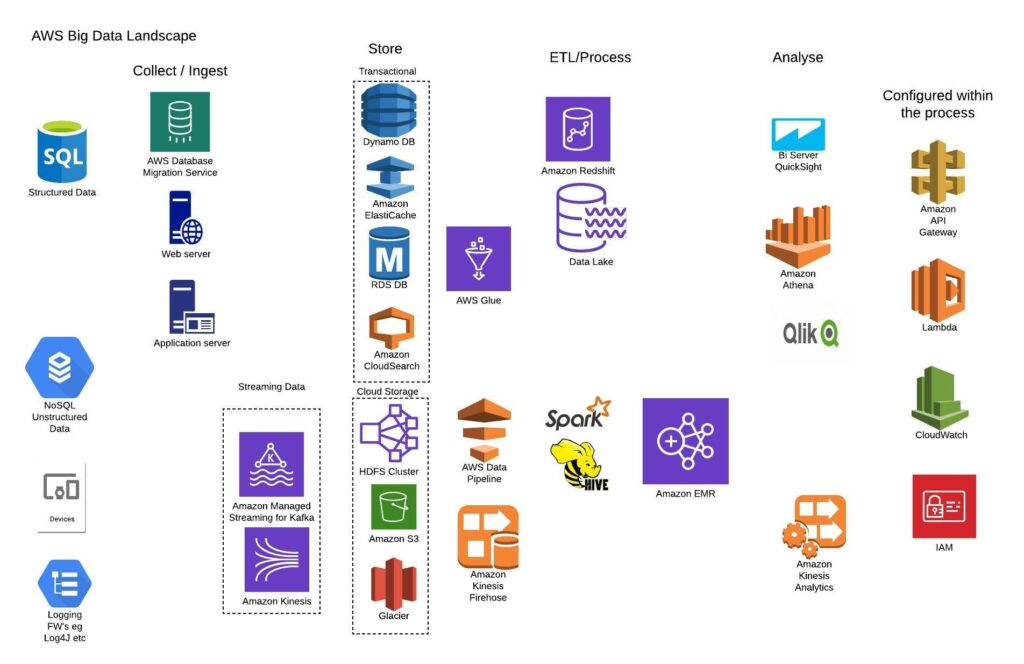
There are many ways to construct a big data flow on AWs depending on the time, skills, budgets, objective and operational support.
Key architectural principle is simplicity. A second is cost control.
Types of Data:
- Transaction – usually SQL sometimes NoSQL
- Unstructured- web, media, cloud– S3, HDFS on Hadoop, EMR (Hadoop), Spark, Hive
- Log files -Kinesis, Kafka
Methods of using Big Data:
- Batch
- Stream, real time eg clickstreams, IoT
- Machine Learning/Predictive
Delivery:
- Virtual – EC2 Kafka
- Managed – EMR Hadoop Cluster with Spark, Kafka, Kinesis
- Serverless-Lambda, Glue, Athena (SQL analytics)
Architecture Principles
- Decouple the process flow Data – ingest – store – ETL or process – analyse
- Right tools for right job
- Leverage Managed and Serverless
- Use event-journal design patterns
- -immutable data lakes, materialised views
- Cost control
- Machine Learning connected to models, app services
- Decouple Compute from Storage (HBase with S3 for eg)
- Tier Data between Hot and Cold needs– HDFS (frequent)-S3-Glacier (cold)
- Types of DB are related to schemas, types, access and retrieval, OLTP vs. OLAP, transactional vs storage
ETL – normalised view of different data sets and schemas eg Glue analyses, CSV, JSON, Parquet