The icebergth is hereth.
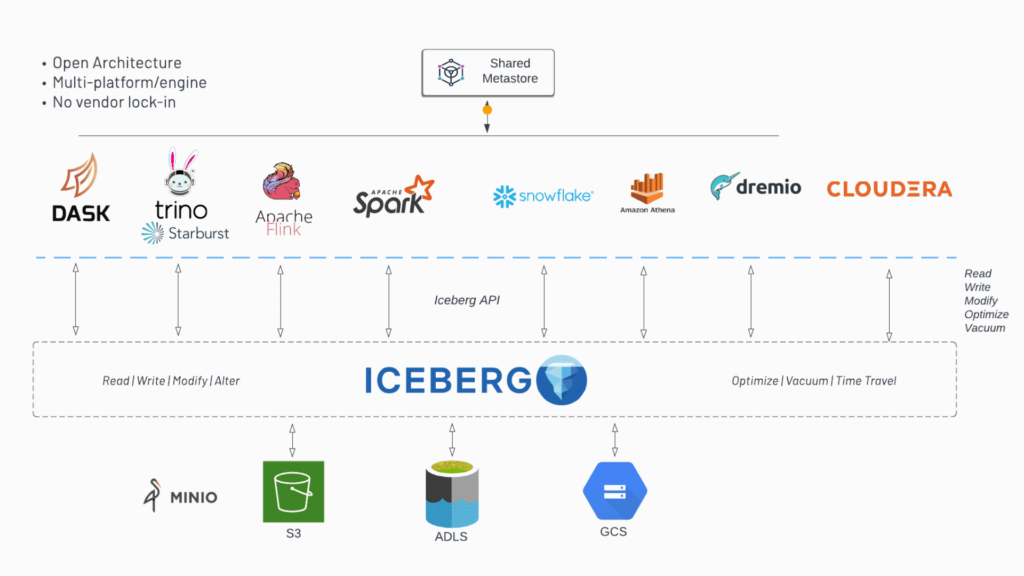
Apache Iceberg is an open-source table format for large-scale data systems, designed to provide efficient and reliable management of structured data in distributed environments. It offers features essential for data warehousing and analytics workloads, such as atomic transactions, schema evolution, and efficient data pruning. Iceberg is built to address the limitations of existing table formats like Apache Parquet and Apache ORC.
Key features of Apache Iceberg include:
1. Atomic Transactions: Iceberg ensures ACID (Atomicity, Consistency, Isolation, Durability) properties for write operations, allowing multiple operations to be committed atomically. This ensures data consistency and reliability even in the face of failures.
2. Schema Evolution: Iceberg supports schema evolution, allowing changes to the table schema without disrupting existing data or requiring expensive metadata rebuilds. This feature facilitates the seamless evolution of data schemas over time.
3. Partitioning and Sorting: Iceberg provides efficient partitioning and sorting mechanisms to optimize query performance. By organizing data into partitions and maintaining sorted data within each partition, Iceberg minimizes the amount of data scanned during query execution.
4. Time Travel: Iceberg supports time travel queries, enabling users to query historical versions of data stored in the table. This feature is particularly useful for auditing, debugging, and analyzing changes to the dataset over time.
5. Incremental Data Updates: Iceberg allows for efficient incremental updates to the table, enabling users to add, update, or delete records without having to rewrite the entire dataset. This significantly reduces the overhead associated with data updates.
6. Metadata Management: Iceberg maintains comprehensive metadata about the table structure, data files, partitions, and transaction history. This metadata is stored separately from the data files, enabling efficient metadata operations and facilitating compatibility with different storage systems.
7. Compatibility and Ecosystem Integration: Iceberg is designed to integrate seamlessly with existing data processing frameworks and tools, including Apache Spark, Apache Hive, and Apache Flink. It provides APIs and connectors for interacting with Iceberg tables in these environments.
For more detailed information and documentation, you can refer to the official Apache Iceberg website (https://iceberg.apache.org/)
What are the alternatives?
There are lots of other table formats, popular formats include,
1. Delta Lake:
— Delta Lake is an open-source storage layer that brings ACID transactions to Apache Spark and big data workloads. It offers features like ACID transactions, schema evolution, time travel, and unified batch and streaming data processing.
— [Delta Lake]
2. Apache Hudi (Hadoop Upserts Deletes and Incrementals):
— Apache Hudi is a storage abstraction that provides incremental data processing and stream processing capabilities on top of Apache Hadoop. It offers features like upserts, deletes, and incremental data processing with built-in support for schema evolution and ACID transactions.
— [Apache Hudi]
3. Apache Parquet:
— Apache Parquet is a columnar storage format for Hadoop that provides efficient storage and encoding of structured data. It is widely used in big data processing frameworks like Apache Spark and Apache Hive for data storage and analysis.
— [Apache Parquet]
4. Apache ORC (Optimized Row Columnar):
— Apache ORC is another columnar storage format for Hadoop that offers efficient compression and encoding techniques to reduce storage space and improve query performance. It is commonly used in data warehousing and analytics workloads.
— [Apache ORC]
BYOS – bring your own storage
Firms can use Snowflake and Databricks with Apace Iceberg. Other vendors are following suit. The BYOS pattern will only grow.
ELT gets dramatically minimised
Iceberg should help with issues with ELT or ETL. Rather than have disparate data sources that require constant EL and T, we should have data being updated in place. Provided there are no multi-tenanted issues, you effectively centralise all your data by design.
Imagine if all data sources simply had iceberg backends. Imagine that the data warehouse was also based on iceberg, and your Postgres RDS instance needed no replica because you were simply firing events onto a queue to be put into iceberg. There would be no need for ELT.