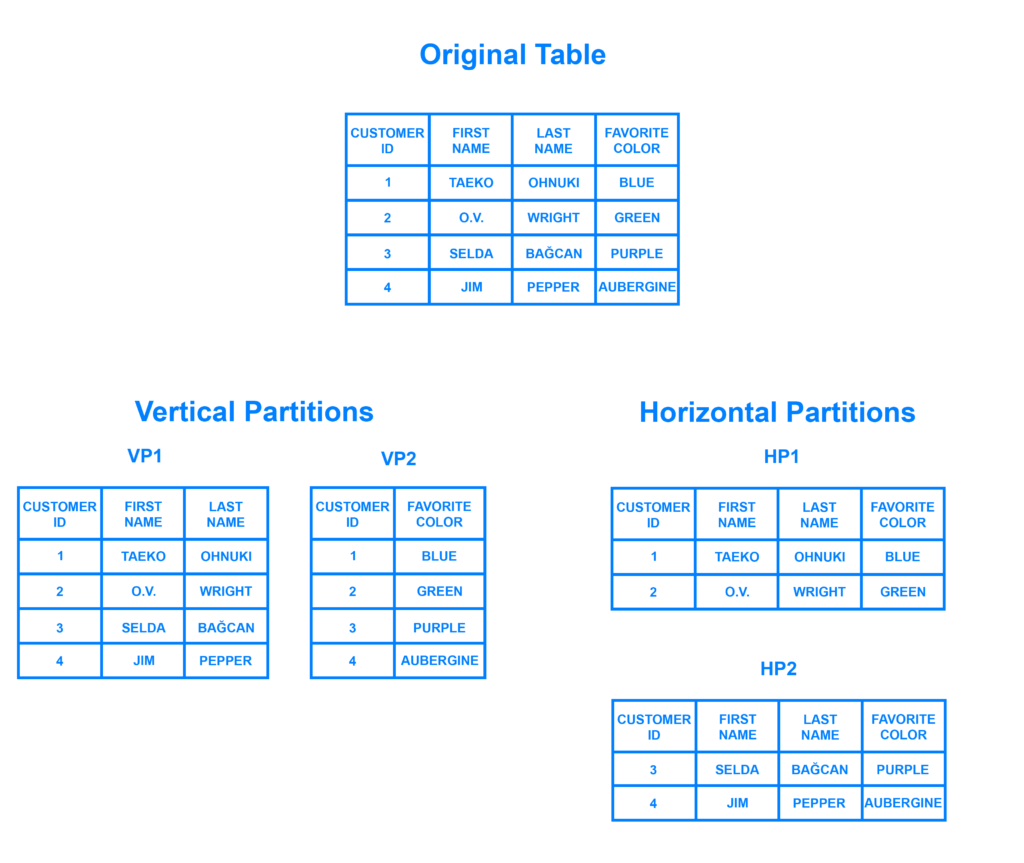
Data files or tables are parsed into smaller units. This is also called ‘partitioning’. A partition is usually performed against a primary attribute that is common across all the records, for example a date. We can partition files before or after we move the source files and tables to the cloud. This will depend on many factors, but often it is easier to migrate data to the cloud than parse it with glue or other tools in the raw object store.
- Partition: A partition is a smaller chunk of your data. Each partition is processed by a task.
- Block Size: This is the size of each partition. The default block size in many big data environments is 128 MB.
Example Calculation
Let’s assume you have a 10 GB file, and the default block size is 128 MB. We can calculate the number of partitions:
File Size in MB:
- Since 1 GB = 1024 MB, your 10 GB file is:
- 10 GB * 1024 MB = 10240 MB
2. Number of Partitions:
- Divide the total file size by the block size:
10240 MB / 128 MB/block = 80 partitions
So, for a 10 GB file, there would be 80 partitions. Using this calculation we can develop both code and logic; and the underlying infrastructure to support processing, including parallel processing.
Compute
- Maximum Parallel Tasks: With a 10-node cluster, where each node has 15 CPU cores, you can run up to 150 tasks simultaneously.
- Number of Partitions: For a 10 GB file, assuming a default block size of 128 MB, there would be 80 partitions.