Iceberg Cometh
Open table formats, such as Apache Iceberg, enable scale-out data warehousing directly on a data lake. This architecture has become known as a data lakehouse. Since the creation of enterprise data warehouses, such as Teradata and Oracle, customers have been locked in by proprietary data storage (i.e., table formats and metadata catalogs). Data lakes were open, but couldn’t deliver the same functionality and performance as data warehouses. Customers have adopted open table formats to achieve the combination of vendor-agnostic data representation and data warehouse capabilities and performance. In this blog post, we explore the journey of open table formats, and why the industry has selected Apache Iceberg as the open standard.
Tip of an Iceberg
The story begins in 2019 when Netflix contributed Iceberg to the Apache Software Foundation. Netflix was already using Iceberg internally, and once it became an open source project it was quickly adopted by many other large tech companies such as Apple, Adobe, Airbnb, and others. This move marked a strategic shift towards an open, vendor-agnostic solution for representing tables in object storage.
While Delta Lake emerged around the same time frame, it was not (and still is not) an open format. Over time, some of its source code was released, but key elements remained proprietary. For example, a Delta Lake-based lakehouse with the Databricks Unity catalog cannot accept writes from non-Databricks compute engines, and other catalogs impose serious restrictions, such as not supporting concurrent writes. Iceberg clearly stood out in that it was vendor agnostic, and that dozens of leading companies collaborate on the roadmap and actively contribute to the project. Iceberg quickly gained traction due to its open nature and compatibility with modern data teams’ needs.
Industry Adoption and Validation
Throughout 2021–2022, Apache Iceberg and Delta Lake were locked in a two-horse race. The tide began to turn in 2023 as most of the major players in the data lake/lakehouse market rallied behind Iceberg.
- AWS adopted Iceberg as its table format for its data services, such as Athena, Redshift, Glue.
- Snowflake adopted Iceberg as a new native format alongside its existing table format.
- Google adopted Iceberg as its table format for its data services, such as BigQuery and BigLake.
- Confluent adopted Iceberg as the format behind Tableflow, a technology that feeds Apache Kafka data into the lake.
- Microsoft adopted Iceberg as a way to share data across Snowflake and Fabric.
- Ryan Blue and several other Netflix engineers started a company called Tabular to build an Iceberg catalog service.
- Dozens of open source and commercial projects have adopted Iceberg support as their native table format.
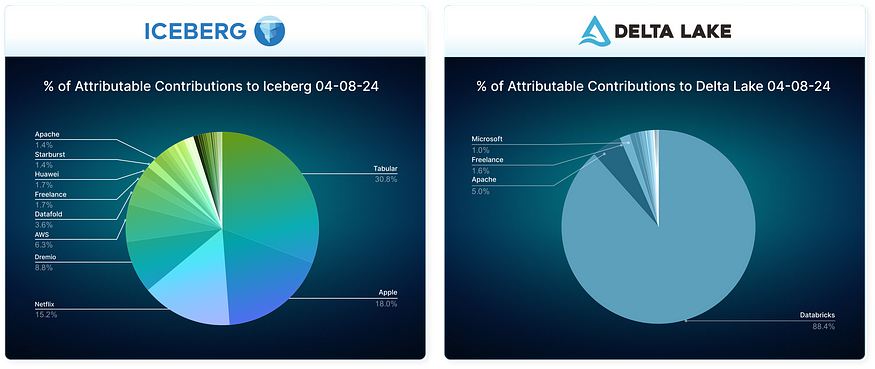
Developer Community
Iceberg distinguishes itself not only through its extensive ecosystem of technologies and products but also by the wide array of companies contributing to the project. This diversity brings several advantages, including rapid innovation and assurance that the project will continue to evolve independently of any single company. The following diagram illustrates the variety of contributors to the Iceberg project compared to those of the Delta Lake project: