Given the wide variety of data sources, data processes and use cases around data, including ‘Big Data’ it is necessary to understand data types and relevant databases to support those datatypes. Each data type may have a unique flow to how that data is used and analysed. An example of this would be using a Document NoSQL database to aggregate and report on Log data (systems, operations) within a cloud platform.
Relational databases
The simplest ‘data model’ is that of a ‘Flat File’. Flat-file storage will not be a valid data model for most firms. But using a process known as ‘normalisation’ we can turn the Flat File into a relational database. Normalisation is a set of rules that work together to reduce redundancy, increase reliability, and improve the consistency of data storage.
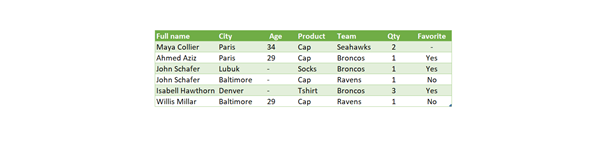
A relational database is built to store structured data so it can be collected, updated, and queried easily. Relational databases rely on a series of structures, called tables, to hold the collected data. These tables are navigated using the structured query language, or SQL.
Logically, relational database tables group data based on a person, place, thing, or event related to that data. These groupings are referred to as entities. Each entity is stored as a table.
A column, known as a field, is used to describe one attribute of the entity. A row, known as a record, in the table represents a single instance of an entity.
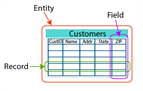
Think of a spreadsheet, where each row has a cell for each column. Each cell can contain a value. Rules within the schema define if the attribute is required or optional.
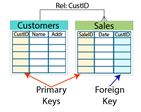
Relationships are created by first ensuring that every row in a table is unique. This is done by creating a primary key. This primary key value can then be used to create relationships between tables. A foreign key is a field that uses the values from a primary key in another table to define a record in the current table. This act is what builds the relationship. Some database engines can enforce this relationship to ensure that only values from the primary key can be used in the foreign key.
Strengths
- Provides ACID compliance
- Data is easily stored, edited and retrieved using a common SQL language
- The structure can be scaled up quickly
Weaknesses
- Struggle storing unstructured data
- Querying can be slow due to complex join requirements
- The schema can make scaling out quite difficult
The image below provides an example of how you can take flat-file data and turn it into a relational data structure. A Flat File spreadsheet may contain in one xls tab, the Customer Information, the Product, and Order information. You can take the different areas and create tables with unique Primary and Secondary Keys which can be used to query the data; namely, Customer, Product and Order tables.

Structured Data
Structured data is classified as data that is stored in a database or database management system (DBMS). A database is a structured set of data held in a computer—one that is accessible in various ways. A DBMS provides structure to the data, the ability to maintain the data throughout its lifecycle, and the ability to manage interactions with other processes and systems. Different database management systems manage data organization in different ways to achieve specific goals, such as complex analysis, rapid relationship navigation, or session state retrieval.
Relational Systems: OLTP, OLAP
There are two main ways—known as information systems—of organizing data within a relational database. The data can be organized to focus on the storage of transactions or the process of analysing transactions.
Transactional databases are called online transaction processing (OLTP) databases. The data gathered by OLTP databases is often fed into another type of database that focuses on analysing the transactional data. Online analytical processing (OLAP) databases gather data from OLTP systems for the purpose of organizing it for analytical operations.
Relational database pros and cons
The primary benefit of a relational database using SQL is that it is proven technology that is widely adopted and understood. There is less risk involved with a relational database, especially due to ACID compliance and a large community of experts in the field. There is an expectation of very good transactional latency, especially on appropriately sized hardware, and relational databases are considered outstanding for OLTP for relatively small data sets.
There are scalability concerns with a relational database. As data sets grow, the only way to maintain performance is to increase the hardware capacities of the servers that run the application. Another key issue is the fixed schema of relational databases. It is difficult to make non-disruptive changes to the underlying database architectures, which can affect development times for new functionality.
Preparing relational data for data processing
When working with a relational database, you must pay attention to how the data will be used within the data analysis solution. It is very common to perform multiple types of analytics on the same data. OLTP data may need to be transformed into a denormalized form and placed into a data warehouse or data mart. OLAP data may not require any transformation. There may even be opportunities to transform data into staging databases that can be used as a data source for other analytic processes.
Semi structured and unstructured data are often stored in non-relational database systems, sometimes called NoSQL databases. This term can cause a bit of confusion. It is important to remember that SQL is a way of querying data. It implies precise structure. Non-relational or NoSQL does not mean the data stored cannot be queried using SQL. A better way to think of it is not only SQL.
Document stores are a type of non-relational database that store semi structured and unstructured data in the form of files. These files range in form but include JSON, BSON, and XML. The files can be navigated using numerous languages including Python and Node.js.
Logically, files contain data stored as a series of elements. Each element is an instance of a person, place, thing, or event. For instance, the document store may hold a series of log files from a set of servers. These log files can each contain the specifics for that system without concern for what the log files in other systems contain.
Strengths:
- Flexibility
- No need to plan for a specific type of data when creating one
- Easy to scale
Weaknesses:
- Sacrifice ACID compliance for flexibility
- Cannot query across files
Key-value stores
Key-value databases are a type of non-relational database that store unstructured data in the form of key-value pairs.
Logically, data is stored in a single table. Within the table, the values are associated with a specific key. The values are stored in the form of blob objects and do not require a predefined schema. The values can be of nearly any type.
Strengths:
- Very flexible
- Able to handle a wide variety of data types
- Keys are linked directly to their values with no need for indexing or complex join operations
- Content of a key can easily be copied to other systems without reprogramming the data
Weaknesses:
- Impossible to query values because they are stored as a single blob
- Updating or editing the content of a value is quite difficult
- Not all objects are easily modelled as key-value pairs
What is a blob? A blob is a binary large object namely, sounds and multimedia files. Blob’s have a comparatively larger size than most data types and can contain up to gigabytes of data.
A relational database on the other hand will store data in the form of a table which contains rows, with each row representing for example, a single product that can be sold. Each column stores an attribute of that product: The Product ID, Product Name, Supplier, Price, and Unit. Note that both products have an entry for every attribute. A column is also called a field. A row is called a record.

Imagine that now the needs of the business have changed. You need to add a new column to track each product’s rating. Not all products have a rating yet, so you need to allow the column to accept NULL values.
To add a new column to the table, you must:
- Execute a SQL command to add the column.
- The table now contains an empty column.
- Populate the new column with a value for each existing record.
When the same requirement is placed on data in a non-relational database, the remedy is quite different. You simply add the data for that record. With a non-relational database, each record can have its own set of attributes. This flexibility is one of the greatest benefits of non-relational databases.

Graph databases are purpose-built to store any type of data: structured, semi-structured, or unstructured. The purpose for organization in a graph database is to navigate relationships. Data within the database is queried using specific languages associated with the software tool you have implemented.
Logically, data is stored as a node, and edges store information on the relationships between nodes. An edge always has a start node, end node, type, and direction, and an edge can describe parent-child relationships, actions, ownership, and the like. There is no limit to the number and kind of relationships a node can have.
Strengths:
- Allow simple, fast retrieval of complex hierarchical structures
- Great for real-time big data mining
- Can rapidly identify common data points between nodes
- Great for making relevant recommendations and allowing for rapid querying of those relationships
Weaknesses:
- Cannot adequately store transactional data
- Analysts must learn new languages to query the data
- Performing analytics on the data may not be as efficient as with other database types
Non-relational database pros and cons
Non-relational databases have the primary benefit of going beyond the limitations of relational databases, especially through dynamic schemas, which give DBAs the ability to update schemas on the fly. This leads to faster development cycles and less downtime. Also, because non-relational databases can be deployed on massively distributed commodity servers, these databases have an advantage in scaling and can handle much larger data sets.
The massive distribution does have a downside, in the form of “eventual consistency,” which means that data is not instantaneously updated with every change and instead catches up as a background task. Although this is acceptable under many circumstances, it does make ACID compliance difficult to achieve. Note that DynamoDB in AWS which is a popular NoSQL product does support ACID compliance.
Another drawback is that non-relational databases do not perform as well as relational databases in applications that require extremely low transactional latency. Finally, although non-relational platforms are constantly developing and growing, there isn’t nearly the same maturity as relational technologies or the same amount of field expertise.
Comparing relational and non-relational databases
There are many factors that can help you determine which database type is best for a new project or program you are developing. Below are the key characteristics of all three database types we have covered.
| Characteristic | Relational | Non-relational | Graph |
| Representation | Multiple tables, each containing columns and rows | Collection of documents Single table with keys and values | Collections of nodes and relationships |
| Data design | Normalized relational or dimensional data warehouse. | Denormalized document, wide column or key value | Denormalized entity relationship |
| Optimized | Optimized for storage | Optimized for compute | Optimized for relationships |
| Query style | Language: SQL | Language: many Uses object querying | Language: many Uses object querying |
| Scaling | Scale vertically | Scale horizontally | Hybrid |
| Implementation | OLTP business systems, OLAP data warehouse | OLTP web/mobile apps | OLTP web/mobile app |
Examples:
A multi-dimensional data warehouse is best suited for a relational database.
Log files are generally produced in the form of XML or JSON files, which are very well suited for storage in a document database.
Data collected from online gaming websites is often very rapid in generation and temporary in nature. This data is well suited for a key-value database.
Transactional data from a social subscription service could be stored in a relational database, but due to the social component, it would be better suited to the advantages gained by using a graph database.