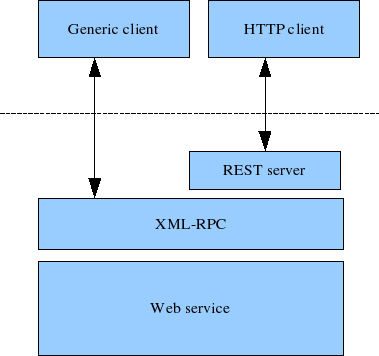
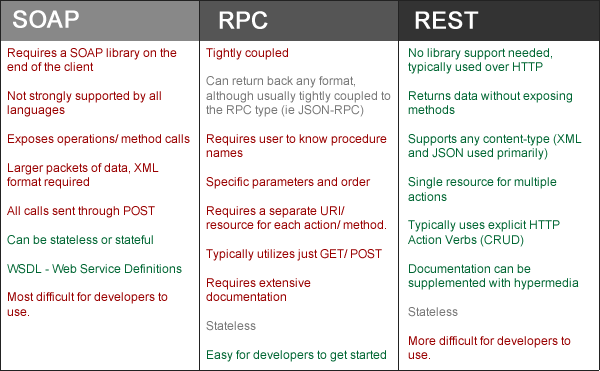
RPC and Middleware
Distributed computing, with clients calling servers or remote resources was originally premised on Remote procedure calls (RPC), a protocol which has been around since the 1970s. The RPC model tries to make a request to a remote network service look the same as calling a function or method in your programming language, within the same process (this abstraction is called location transparency). Although RPC seems convenient at first, the approach is fundamentally flawed. A network request is very different from a local function call of course.
A network request is natively unpredictable: the request or response may be lost due to a network problem, or the remote machine may be slow or unavailable, and such problems are entirely outside of your control. Network problems are common, so you have to anticipate them, for example by retrying a failed request. A local function call either returns a result, or throws an exception, or never returns (because it goes into an infinite loop or the process crashes).
As well in most systems it is common that the client and the service may be implemented in different programming languages, so the RPC framework must translate datatypes from one language into another. This leads to issues, since not all languages have the same types with for example, JavaScript’s problems with numbers greater than 253. Such problems don’t exist in a single process written in a single language.
Service compatibility is made harder by the fact that RPC is often used for communication across organizational boundaries, so the provider of a service often has no control over its clients and cannot force them to upgrade. Thus, compatibility needs to be maintained for a long time, perhaps indefinitely. If a compatibility-breaking change is required, the service provider often ends up maintaining multiple versions of the service API side by side. There is no agreement on how API versioning should work (i.e., how a client can indicate which version of the API it wants to use).
REST
Part of the appeal of REST is that it doesn’t try to hide the fact that it’s a network protocol (although this doesn’t seem to stop people from building RPC libraries on top of REST). Due to its design philosophy REST seems to be the predominant style for public APIs. The focus of RPC frameworks is on requests between services owned by the same organization, typically within the same datacenter.
RESTful APIS on the other hand are used for requests which can span many networks, involving different, even nested services. RESTful APIs most commonly use JSON (without a formally specified schema) for responses, and JSON or URI-encoded/form-encoded request parameters for requests. Adding optional request parameters and adding new fields to response objects are usually considered changes that maintain compatibility.
For RESTful APIs, common approaches are to use a version number in the URL or in the HTTP Accept header. For services that use API keys to identify a particular client, another option is to store a client’s requested API version on the server and to allow this version selection to be updated through a separate administrative interface.
REST APIs are a significant feature within distributed and especially asynchronous systems.
Asynchroncity and Message Broking
A communication pattern is asynchronous: the sender doesn’t wait for the message to be delivered, but simply sends it and then forgets about
Many systems deploy an asynchronous message model. This is somewhere between RPC and databases. They are similar to RPC in that a client’s request (usually called a message) is delivered to another process with low latency. They are similar to databases in that the message is not sent via a direct network connection but goes via an intermediary called a message broker (also called a message queue or message-oriented middleware), which stores the message temporarily.
Using a message broker has several advantages compared to direct RPC: It can act as a buffer if the recipient is unavailable or overloaded, and thus improve system reliability. It can automatically redeliver messages to a process that has crashed, and thus prevent messages from being lost. It avoids the sender needing to know the IP address and port number of the recipient (which is particularly useful in a cloud deployment where virtual machines often come and go). It allows one message to be sent to several recipients. It logically decouples the sender from the recipient (the sender just publishes messages and doesn’t care who consumes them).
In the past, the landscape of message brokers was dominated by commercial enterprise software from companies such as TIBCO, IBM WebSphere, and webMethods. More recently, open source implementations such as RabbitMQ, ActiveMQ, HornetQ, NATS, and Apache Kafka have become popular.
Producers and Consumers
Message brokers typically don’t enforce any particular data model — a message is just a sequence of bytes with some metadata, so you can use any encoding format. If the encoding is backward and forward compatible, you have the greatest flexibility to change publishers and consumers independently and deploy them in any order. One process sends a message to a named queue or topic, and the broker ensures that the message is delivered to one or more consumers of or subscribers to that queue or topic. There can be many producers and many consumers on the same topic. A topic provides only one-way dataflow.
==END