Serverless Computing is a misnomer. It is really Functions-as-a-Service, or FaaS. A FaaS model allows you to ‘rent’ the AWS infrastructure by using Lambda functions. You do not have to provision the underlying instance, database or service resources. AWS will provide these for you, generating the necessary underlying infrastructure via Lambda function calls and code. Servers and associated compute-network-storage, operation system, scalability and security services are still being used of course.
The main difference is that instead of having to design a VPC-EC2-IAM-Auto Scaling-Reliable platform, you can use Lambda code, written in Java, .Net, Python or Node.JS, to invoke these services for you. Hence the best way to describe Serverless is really FaaS, or writing code which the cloud provider will then process, and establish the necessary services and compute power, to process your functional requests.
Use Cases
There are 3 main usage scenarios for FaaS and Lambda on AWS:
1 ) Nanoservices, where there is one function for one job; and where every single one of the functions only deals with one single job. However, this approach will result in a lot of functions. Quite likely our functions will also share dependencies, which means a lot of code writing and complexity. For example, we will need one Lambda function for ‘get’, one Lambda function for ‘post’, and one Lambda function for ‘put’. This entails a lot of overhead in operations and code maintenance.
2 ) Therefore a second pattern is one more suitable for HTTP interfaces in that we have one function and multiple jobs or cases. As an example, one serverless function could handle all the get, post, and put operations for your resources. Creating one function with a number interfaces is generally a more efficient way to create serverless functions.
3 ) A third use case is the ‘monolithic approach’. This is where you manage all of your interactions between your cloud services and your servers with only a minimal number of functions via an interface aggregator. There are several services in the market that can provide such a consolidation.
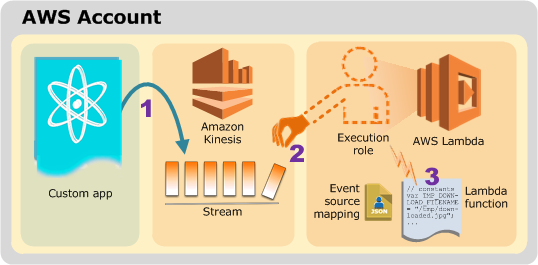
FaaS Scalability
Lambda functions are stateless, meaning that they can quickly scale. More than one serverless function can be added to a single source. Serverless is fast and will execute your code within milliseconds, and serverless manages all of the Compute resources requirement for your function. Lambda also provides built in logging and monitoring through services like Amazon Cloud Watch.
Example: A Streaming Application
A good use case for FaaS is real time streaming or data processing. Streaming applications are usually not ‘streaming’ (and they are, as with AWS Kinesis, ‘Pull’ architectures, see here for a real world analysis). They are used in analytics in which we have lots of data, updated constantly, which is processed, and analysed in some fashion.
In a ‘normal’ AWS architecture there are many services to worry about, when deploying a platform to manage a streaming application. These include:
-Stand up a server and provision it to run our application code.
-Go into EC2, select a machine and an Amazon Machine Image, select the memory, configure our storage, and configure our security groups, network access control lists
-Install the application runtime on an operating system, so that might be Java or Node or C#.
-Write a trigger or a Dropbox to process a file system or an S3 bucket when a file was added.
-After running our conversion function, we then save the file back to the appropriate storage.
The Lambda approach:
We can replace our ‘manual’ approach by utilising Lambda.
For example, we can take out the provisioning management and maintenance of the server through a Lambda script where AWS executes our code only when it’s needed and scales the environment automatically. That will service or support a few requests per day up to thousands per second. With these capabilities, you can use AWS Lambda to easily build data processing triggers around AWS services such as Amazon S3, Dynamo DB, or Amazon Kinesis. This streaming data is stored and processed, and we can create our own backend that operates with AWS doing all of the scale and performance and security. Now, we do get to set some parameters. We can set the memory allocation, and the larger the memory also represents an increase in the processor and network performance.
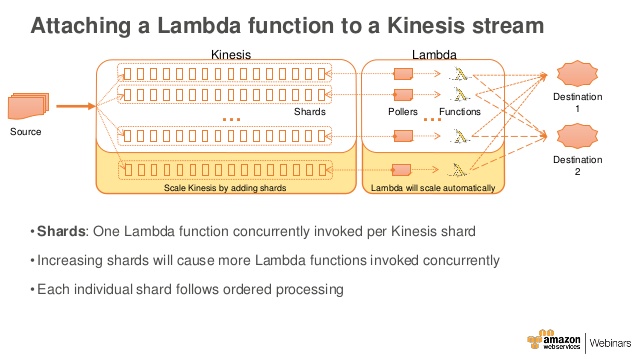
(Image: AWS webinar training on Lambda)
Behind the scenes, AWS is using containers and when you request a Lambda function, AWS creates for the request, an instance within a container. The first request to the instance is generally a little slower than subsequent requests, but that difference is minimal. So realtime event data, for example, sent to Amazon Kinesis, which provides large-scale, durable storage of the events for 24 hours. And it also allows multiple AWS Lambda functions to process the same events.
As well we can provision the needed capacity of a Dynamo DB table just by changing the configuration values. We might also have another Lambda function that stores incoming events in Amazon S3, which is more durable and cost effective, and a great long-term storage solution. Storing data on Amazon S3 makes the data easily accessible for downstream processing and any other analytics that we want to go through. So ultimately, Lambda is going to give us a much simpler architecture for this type of streaming application.
Benefits and Caveats
Some Benefits:
-Zero admin: With a Serverless application, you don’t have to worry about the server machine or services and resources needed.
-Pay for usage: You pay for the time that your function is executing, rather than the time a machine is provisioned for.
-Utility model: We only need to scale a single function. We don’t need to scale an entire system.
-Built in fault tolerance and high availability by design: Immediately we have multiple availability zones in each region to help protect our code against individual machine or data sender failure. That means that functions running on the service provide predictable and reliable operational performance. There’s no maintenance windows or scheduled down times for us to worry about.
A caveat about Lambda and serverless/FaaS scripts is that they are time-based. If we have a script which runs longer than 60 seconds, we are better off in both performance and costs, to use EC2. With FaaS, we have to use that microservice approach to get the benefit of reduced maintenance time. A second caveat is that FaaS is good for newly built, micro-service architectures. It makes no sense to decompose and rewrite an existing app we can migrate to a more classic non FaaS platform. However, if I am building a microservice with Restful APIs, cloud native code and I am targeting the processing of micro-services (eg. analytics), than FaaS is perfectly sensible, more efficient and cost effective.