Serverless computing does not replace server-based computing. In event and microservice architectures, Lambda and server-less functions can serve important purposes. From using Lambda on AWS the following is a summary of tips and tricks.
What is Lambda
Lambda on AWS was designed to target event driven architectures. It is a ‘deploy and forget’ model. A developer provides the code to the Lambda service via a console, or CLI and describes when it should be run (whether on-demand or in response to some event) and AWS will manage the provisioning of the compute, network and storage, including CPU, disk space, memory, networking, OS updates. AWS will also manage the underlying updates, code deployment to the required locations, and scaling up to match demand. It is in essence a managed server-infrastructure
Lambda code is stored on S3, metadata for the function is stored in DynamoDB, an execution occurs from Amazon Linux EC2 instances, and the function assumes an IAM role. Each function is designed to do just a single or a few common processes.
Lambda functionality
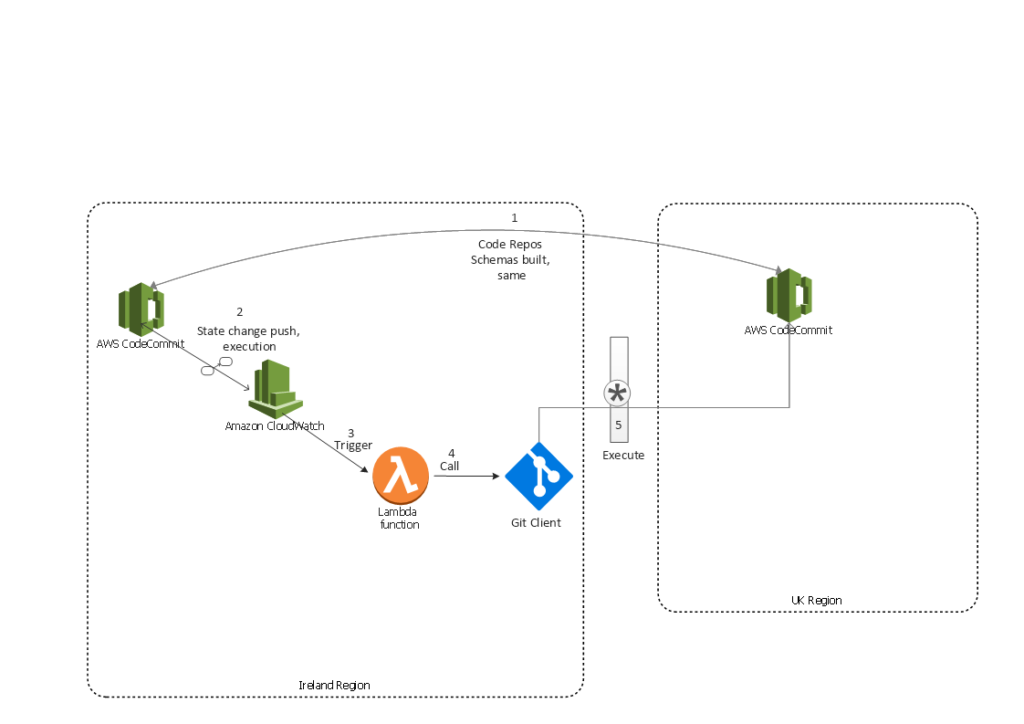
Each Lambda function can be treated as a separate project. You should create a GitHub/CodeCommit project for each Lambda function and treat Lambda as you would any code base with proper version control, secure access etc. Key aspects include:
~Each Lambda function must function independently (i.e. it cannot rely on dependencies within a different project unless they are copied to the project before deployment).
~Lambda functions are uploaded to Lambda as a ZIP file. The ZIP file can be uploaded from the console, the command line, or placed on S3 (preferable for larger files). AWS takes care of downloading the ZIP to the backend resources it manages.
~Each successive update to the code only requires you to re-upload another ZIP to replace the previous. Again, AWS will manage the deployment of the new code to its resources.
~Lambda supports code written in Node.js, Java, and Python.
~Use CloudWatch. Every Lambda execution will log its events (and any in-app console.log statements) to the CloudWatch log group.
~Triggers from: S3 create and remove events, DynamoDB row updates, CloudWatch Logs “put” events, SNS notifications, Kinesis events, and Alexa voice commands.
Limitations of Lambda
~Timeout value will limit your function to a certain running time. Timeout values range from 1 second to 300 seconds.
~1.5 GB of memory
~Lambda functions cannot respond directly to HTTP requests (unless paired with AWS API Gateway), or run long-running processes in the background.
Security
IAM roles are required for all Lambda functions. These roles define a specific policy which grant “allow” or “deny” permissions to other AWS resources. These permissions for example, could allow the Lambda function to perform CloudWatch Logs actions such as creating a log group, creating a log stream, and saving log entries into that stream.
When NOT to Use Lambda
If your application:
- Relies on a heavily configured AMI
- Has multiple dependencies to set up before running
- Has developers frequently using SSH to the host instances
- Relies on native OS interaction (such as user accounts)
- Requires extensive testing or reconfiguration each time the host OS updates
- Applies the latest OS patches and security updates minutes after they’re released
- Requires the ability to directly access system, access, and security logs of the host
- Utilizes utilities that change the underlying OS settings or preferences (i.e. max open network connections, max file handlers, etc.)
- Has auditing, compliance, or regulatory needs which require you to save snapshots of the host OS during a security incident
- Runs on any optimized EC2 instance class
- Needs a custom, OS-level tuning before running
- Is vital and you need to know allotted networking speeds, CPU class, or other environment details of the instance running your application
- Is extremely dependent on GPU processing
If more than a few of the above are true then don’t use Lambda.
What is Lambda really good at?
Lambda excels at providing immediate, event-driven responses to triggers within an environment. Currently, it is not designed as a catch-all replacement for a traditional server. The current timeout of 300 seconds makes it quite clear that AWS is designing this as a reactive, rather than long-running, service.
Tasks of this nature include essentially any form of AWS service event: objects uploaded to S3, DynamoDB table updates, CloudWatch Logs log deliveries, SNS topic entries, etc. Because of the existing AWS development pattern, any changes to these services previously required a polling mechanism to detect for most use cases.
Polling problem
Lambda solves the polling problem by creating an on-demand response to particular events. Developers no longer have to constantly check for new S3 objects, new CloudWatch logs, or DynamoDB updates, because AWS has developed an environment whereby those events are pushed to Lambda rather than pulled by traditional AWS resources accessing the API.
If the script can execute in under five minutes and doesn’t rely on copious amounts of local resources, it can probably be replaced by Lambda. If each script is replaced with a Lambda function, the permissions can be much more narrowly applied, failures are much more easily noticed, deployments can be easily triggered, logs are aggregated in one place, and the underlying server management is handled by AWS. For a busy infrastructure administrator, this can mean the difference between spending hours ensuring hundreds of scripts execute across a fleet of EC2 servers and simply setting up CloudWatch alerts for failed Lambda executions.
eg
Starting a function
These methods of starting a function are referred to by AWS as “hot” and “cold” executions. During a “hot” execution, the function has already been invoked and initialized in the past 10-15 minutes and simply re-executes the event handler. Response times for hot executions are usually determined only by the time requirements of the code itself.
Although the relationship isn’t exactly linear, it is important to keep your ZIPs as small as possible. Removing README, help, documentation, unused module, and other files can help in reducing cold boot times.
You should establish a scheduled task to invoke your function every nine minutes, which can be invoked from CloudWatch.
==END