Note on GDPR
- GDPR: https://ico.org.uk/for-organisations/data-protection-reform/overview-of-the-gdpr/
- Purpose: Client information confidentiality, security of all information, right to be forgotten, secure access for EU – UK based information systems.
1 ) Masking: 3 use cases: Test data, live data in transit, production data at rest (or used by an Application).
GDPR uses terms like pseudonymisation (masking). Article 4 defines pseudonymisation (masking) as:
“the processing of personal data in such a manner that the personal data can no longer be attributed to a specific data subject without the use of additional information, provided that such additional information is kept separately and is subject to technical and organisational measures to ensure that the personal data are not attributed to an identified or identifiable natural person”
This could include:
- an encryption key or mapping table,
- making sure that the data cannot be used to identify an individual
- removing direct identifiers, ideally prevent indirect identifiers from being combined and used (eg name from one part of the system, address from another, and bank card # from another)
A separate identifying data – like an encryption key – should be kept in a separate location and subject to tight security controls.
2 ) Issue: What data do we need to mask and does production encryption satisfy GDPR? Do we need a platform to manage the masking life cycle?
3 ) Production Data and Dynamic Masking
Static Masking will not be suitable for most cloud based client applications given GDPR. Assumptions:
- All production data used by an application, that pertains to consumer information, will need to be masked
- We will need to identify the relevant datastores, tables etc. where GDPR information is stored
- Usually Dynamic Masking of Stored Procedures is problematic
- Any database dependent query where the execution plan is in the db, will have issues to mask
- SQL queries are pretty straightforward to mask
- Need to mask request and response level re the above by parsing SPs, Views etc at the db level
- Quite likely you will need a Masking Platform (reasons below) for complex cloud architectures
4 ) Production Data Masking – 2 Basic Methods
There are two basic ways for ‘in-place’ data masking which do not transform:
- Copying an entire database and then masking, (eg for Testing)
- Or copying all of the data into a new database prior to masking. In this case the data is moved and masked at destination (export file, E-L process).
Why do one of the above?
- Use the databases’ management and manipulation of data options
- leveraging built-in functions and stored procedures can speed up the masking process, because the database has already parsed the data,
- can also be used for partial updates to existing data files,
- reduces the chance that complex relationships, functions or stored procedures fail to import properly.
5 ) Production Data Masking – Purpose, Process
Protection of the production database is the main purpose of masking, with test data secondary (usually this is the case with most requirements). Given 4) above we would use one of those 2 methods. Caveats:
- Production data generally cannot be removed since the business applications rely upon, so it needs to be protected in place.
- Newer masking (dynamic) products, provide a means of leveraging production applications to provide secured data.
Masking production data – Process:
- Requests for information are analysed against a set of constraints such as user identity, calling application, location, etc.
- If request does not meet established business use cases, the user gets the masked copy of the data. The masking product either alters a user request for data to exclude sensitive information, or modify the data stream before it’s sent back to the user.
- Dynamic and proxy based masking products supplement existing database systems.
Masking Data in the Cloud, does not follow the typical ‘walled off’ approach of network segmentation, firewalls, and access control systems.
For clients the above process would need to be built in for DevOps, testing.
6 ) Dev-OPS
Importantly we need to mask lower level environments like DevOps. Hackers rarely start with a production hack. They usually go after the Dev environment. We have not considered masking our DevOps data in transit or at rest (testing is one use case where we must mask the data, but what about code, and any data within the DevOps environment?).
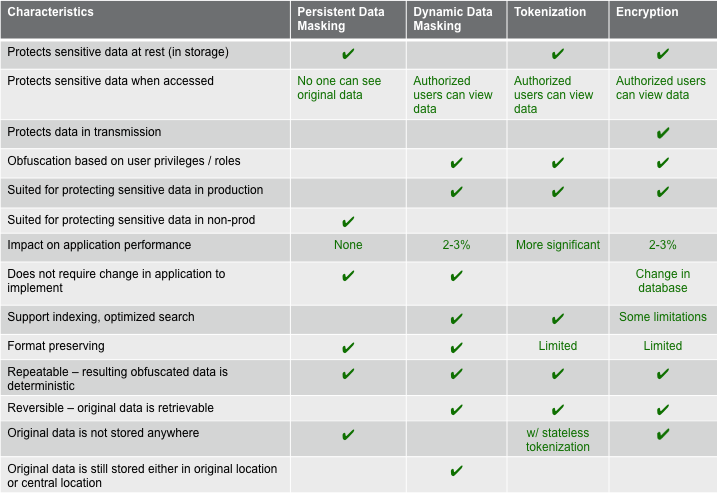
7 ) Masking vs Encryption
Masking and Encryption can be used together in most architectures for data in transit and data at rest. Note that Masking can replace encryption for data at rest.
- Benefits of Masking over Encryption could include: 1.1) better at maintaining relationships within databases than encryption and 1.2) can be applied dynamically, causing fewer application side effects.
- Encryption is deployed as part of the infrastructure (SSL, TSL, in transit, embedded in SAN) or as part of the data masking process — particularly to satisfy regulations like GDPR that prescribe encryption.
8 ) Life Cycle Management
In some architectures encryption and security tokens are add-ons to the Masking process. Masking can provide a data lifecycle management from an initial discovery of what needs to be masked, to what is archived. Encryption is not a life cycle management tool, but is applied to focused data at rest at a specific point.
Discovering what data needs to be masked may not be that easy. A masking platform manages the compliance controls, including which columns of data are to be protected, how they are protected, and where the data resides.
9 ) Masking Platform
Issue with data is that the same data output can be replicated across many apps. How to manage that? There are GDPR Masking Platforms by CA for example which attempt to identify and then mask all data types that could be used as data identifiers.
==END