Redundant Array of Independent Disks (RAID) is a technology for storage units that offers a balanced flow and plenty of benefits, such as better fault tolerance, enhanced reliability, and high performance.
It combines two or more disk storage arrays into logical units that behave like a single drive.
In simple terms, RAID allows multiple hard drives to couple with a single larger storage capacity disk.
Along with creating a larger storage space from numerous smaller drives, it also helps in different performance tasks, such as protection across drives to improve write and read speed and mirroring for data redundancy.
RAID 0 is a standard configuration that uses data striping rather than parity and mirroring for handling data. It is the process of dividing data into different blocks and spreading them across other storage devices, such as solid-state drives (SSDs) or hard disks.
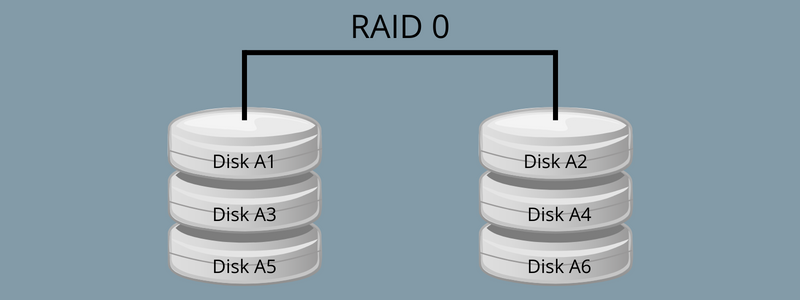
RAID 0 generally improves the system’s performance and relies entirely on RAID for its operations. Also, it helps in creating a large logical volume from various sets of small-capacity drives.
RAID 1, also called disk mirroring, is cloning/copying data to multiple disks. Applications, such as operating systems, email systems, transactional applications, etc., that require high availability and performance can leverage this disk mirroring.
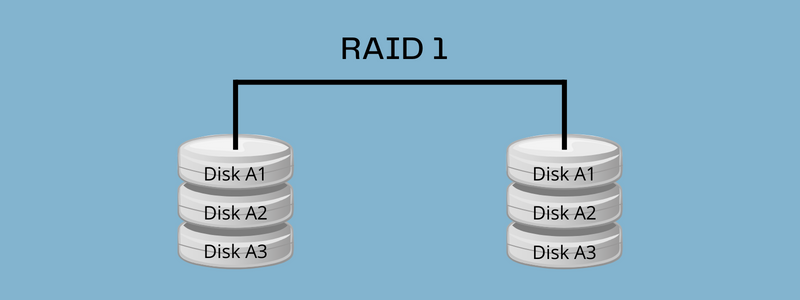
The largest differences between the two levels are their primary data storage functions. RAID 0 and RAID 1 handle their storage devices differently. RAID 0 puts all the drives in the RAID array into a single logical volume, whereas RAID 1 copies the primary drive to multiple drives in the array in real time.
This makes RAID 0 the fastest storage drive for reading and writing operations at a much lower cost. In contrast, RAID 1 becomes the safer option for enterprises for their data integrity and safety. Since both are full of advantages in their path, it will be challenging to decide which one to choose.
Let’s understand the major differences between RAID 0 and RAID 1 side by side:
| RAID 0 | RAID 1 |
| RAID 0 means Redundant Array of Independent Disk level 0. | RAID 1 means Redundant Array of Independent Disk level 1. |
| In the RAID 0 array, disk striping is the primary operation. | In RAID 1, disk mirroring or duplication is the primary operation. |
| The cost is relatively lower. | It is costly as compared to RAID 0. |
| No write penalty. | There is a written penalty. |
| The relative storage capacity is 100%. | The relative storage capacity is 50 %. |
| The read and write performance, along with speed, is high. | The read and write performance and speed are slower than RAID 0. |
| It emphasizes data accessing speed. | It emphasizes data availability. |
| There is no protection. | You will find mirror protection. |
| There is no redundancy, fault tolerance, and mirroring facility. | You will get redundancy, mirroring, and fault tolerance. |
| It’s used when the data reliability is less concerned, but speed is crucial. | It’s used when data loss is not acceptable. |
| Data is unrecoverable. | Data can be quickly recovered in a disaster recovery program. |
| Data is stored in one place. | Data can be stored in multiple places. |
| Two disks contain two different sets of data. | Two disks contain similar sets of data. |
Two concepts can be combined separately to make the best use of both technologies in different areas. If you combine RAID 0 and RAID 1, you can create two combinations:
- RAID 01 (RAID 0+1)
- RAID 10 (RAID 1+0)
The level that comes first in the combination has its function and is later used as the second function of the second level. RAID 0 and RAID 1 combine to make a strip of mirrors, whereas RAID 1 and RAID 0 are connected to make a mirror of strip configuration.
These combinations are known as nested RAID levels. Since RAID 10 comes with greater fault tolerance, it is widely used in many enterprises. It combines disk mirroring and disk striping concepts to simultaneously use 100% storage capacity and data security. This way, you can store more and more data without losing any data, even during a disaster recovery program.