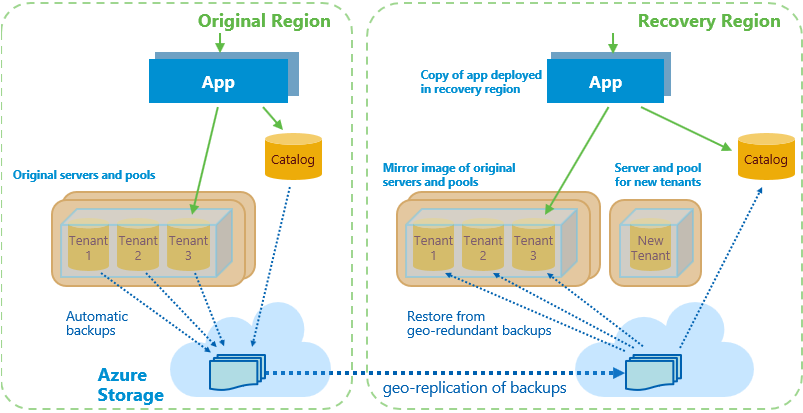
Having an effective, documented and tested disaster recovery plan is one of the most important tools for any IT professional who manages server workloads for their organisation. This is because if things go wrong, you need to have a tried and tested approach to recovering workloads reliably, with a minimal amount of fuss and as quickly as possible.
While there are many important aspects involved in creating a disaster recovery plan it should always start with the development of a Service Catalogue which details each of the services that IT provides to the business along with key information about how those services are delivered and their importance. The concept of a service catalogue comes from the ITIL framework, which is a set of best practices for IT service management.
When creating a service catalogue, don’t fall into the pitfall of just documenting your servers and trying to relate these to services. For example, an email service does not just require a functioning email server, it also requires identity services and networking to be functioning. Therefore, a service catalogue should be created from an end user’s point of view. A good starting point is to speak to the departmental leaders in your business. By asking them what services IT provides to them, you can ensure that you capture all the critical services relied upon by your business. During this process, it is not unusual to discover elements of the service that have been built by the department that IT are not even aware of.
Having identified each of the services that IT deliver to the business you’ll need to build out further information. These includes details of application owners, software vendors contact details and more. In addition to these, two critical areas to discuss with each user department are the Maximum Tolerable Data Loss (MTDL) and Maximum Tolerable Downtime (MTD). MTDL represents the maximum amount of data or transactions the business can afford to lose before facing negative consequences and the MTD refers to the maximum amount of downtime that can be tolerated within the plan.
From these figures, we can agree the Recovery Point Objectives (RPOs) and Recovery Time Objectives (RTOs). The RPO refers to the amount of data loss that can be tolerated within the plan (the maximum time to the last backup or snapshot), while the RTO refers to the maximum amount of downtime that can be tolerated within the plan (how long we have to get a failed service restored and up and running again)
RPO and RTO are important metrics in disaster recovery planning and should be comfortably achievable targets within your DR plan. Your RPO and RTO should be well within the MTDL and MTD to ensure that your business can recover from a disaster as quickly and effectively as possible. Once you have agreed your RPOs and RTOs for each service you can group similar services together to simplify your recovery plan.
It’s also important to regularly review your service catalogue alongside your DR plan. As your business changes and evolves, so too will your IT services. Regularly reviewing your service catalogue and DR plan can help you ensure that you’re still protecting all of the services your business relies upon, and that your DR plan is up to date with any changes.
By linking your RPOs and RTOs to your availability tiers, you can ensure that you have a solid understanding of what needs to be done in the event of a disaster. Remember to ensure you consider system and service dependencies in this planning to ensure everything is able to be recovered in the right order.
In conclusion, having a service catalogue is a critical first step in building an effective disaster recovery solution. By starting with a service catalogue, you can ensure that you capture all the key services relied upon by your business and build out the necessary information to create availability tiers with linked RPOs and RTOs. With a well-thought-out disaster recovery plan in place, you can be confident that you’ll be able to recover workloads quickly and with minimal fuss in the event of a disaster.
| Service Name | Service Description | Related Servers and Services | Application Owners | Maximum Tolerable Data Loss (MTDL) | Maximum Tolerable Downtime (MTDT | Availability Tier | Recovery Point Objective (RPO) | Recovery Time Objective (RTO) |
| Example Service 1 | A description of the service, including what it does and who it’s for. | A list of any servers or services that are related to this service. | The name of the person or team who owns this application. | The amount of data loss that can be tolerated within the plan for this service. | The maximum amount of downtime that can be tolerated within the plan for this service. | The availability tier for this service, e.g., mission-critical, important, or less important. | The amount of data loss that can be tolerated within the plan for this service. | The maximum amount of downtime that can be tolerated within the plan for this service. |
| Example Service 2 | A description of the service, including what it does and who it’s for. | A list of any servers or services that are related to this service. | The name of the person or team who owns this application. | The amount of data loss that can be tolerated within the plan for this service. | The maximum amount of downtime that can be tolerated within the plan for this service. | The availability tier for this service, e.g., mission-critical, important, or less important. | The amount of data loss that can be tolerated within the plan for this service. | The maximum amount of downtime that can be tolerated within the plan for this service. |