Many applications today are data-intensive, not CPU intensive. Raw unlimited CPU power is rarely an architectural or application limiting phenomenon for most applications. Data is the key. The amount, type, complexity and usage of Data to be exact. There are 5 general functional areas that most application databases need to handle:
- Store data so that they, or another application, can find it again later (databases)
- Remember the result of an expensive operation, to speed up reads (caches)
- Allow users to search data by keyword or filter it in various ways (search indexes)
- Send a message to another process, to be handled asynchronously (stream processing)
- Periodically crunch a large amount of accumulated data (batch processing)
With the advent of Cloud services, there are now many new tools and platforms to help with the 5 areas above. We now have a polyglot containing:
- Datastores which are also used as message queues (Redis),
- Message queues with database-like durability guarantees (Apache Kafka or SQS);
- Message Queues which act as event driven real time processing engines (Kinesis);
- Application-managed caching layer (using Memcached or similar),
- Full-text search server (such as Elasticsearch or Solr) separate from the main database,
- NoSQL for large data sets combined with SQL Clustering for transaction processing;
Etc.
Given tools and their purpose we now have a possible architecture for a data system that combines several components. This is called ‘polyglot persistence’.

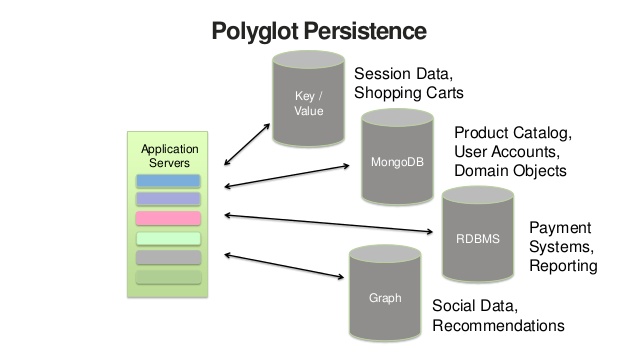
Use Case Examples
Databases handle many different kinds of use cases. For example, in a batch processing system such as Hadoop, we usually care about throughput the number of records we can process per second, or the total time it takes to run a job on a dataset of a certain size. With online systems however, it is usually more important to focus on the server response time, that is, the time between sending a client request and the receiving a response (eg. An order, deleting a shopping cart time, updating a card).
Latency and response time are often used synonymously, but they are not the same. The response time is what the client sees: besides the actual time to process the request (the service time), it includes network delays and queueing delays. Latency is the duration that a request is waiting to be handled during which it is latent, awaiting service. Database design should not confused the two.
Abstractions and models
High-level programming languages are abstractions that hide machine code, CPU registers, and syscalls. SQL is an abstraction that hides complex on-disk and in-memory data structures, concurrent requests from other clients, and inconsistencies after crashes. Of course, when programming in a high-level language, we are still using machine code; we are just not using it directly, because the programming language abstraction saves us from having to think about it. However, finding good abstractions is very hard. In the field of distributed systems, although there are many good algorithms, it is much less clear how we should be packaging them into abstractions that help us keep the complexity of the system at a manageable level.
Data models are perhaps the most important part of developing software, because they have such a profound effect: not only on how the software is written, but also on how we think about the problem that we are solving. Most applications are built by layering one data model on top of another. For each layer, the key question is: how is it represented in terms of the next-lower layer?
For example: As an application developer, you look at the real world (in which there are people, organizations, goods, actions, money flows, sensors, etc.) and model it in terms of objects or data structures, and APIs that manipulate those data structures. Those structures are often specific to your application. When you want to store those data structures, you express them in terms of a general-purpose data model, such as JSON or XML documents, tables in a relational database, or a graph model. The engineers who build the database software may have decided on a way of representing that JSON/XML/relational/graph data in terms of bytes in memory, on disk, or on a network. The representation may allow the data to be queried, searched, manipulated, and processed in various ways. On yet lower levels, hardware engineers have figured out how to represent bytes in terms of electrical currents, pulses of light, magnetic fields, and more.
This means that the models used within an application to the database must be consistent and logically unified to avoid code-to-data-formats mismatches. The application is mostly coded in objects. The data model is not object based however. Object-relational mapping (ORM) frameworks like ActiveRecord and Hibernate reduce the amount of boilerplate code required for this translation layer, but they can’t completely hide the differences between the two models.
RSMO
There are 4 main areas of Database design to provide high end application support, summarised as the RSMO model: Reliability, Scalability, Maintainability, Operability.
Together these 4 areas will provide the buzzwords one hears around Databases, namely; fault tolerance, high availability, ‘self-healing’, and ‘anti-fragility’. Behind the buzzwords are the concrete technical challenges and techniques offered in the RSMO model.
Reliability
A Database system needs to continue to work correctly (performing the correct function at the desired level of performance) even in the face of a fault (hardware or software faults, and even human error). A fault is not the same as a system or systemic error. A fault is defined as an error for a component outside of the mean expected. A failure is the complete failing of the same component. The two are different concepts. When you discuss ‘fault tolerance’, you are creating a system which will function if a component performance degrades outside of its expected mean range. Fault tolerance does not mean component failure. High availability does include component failure. For example, 5-10% of hard disks fail each year. Within the physical hardware layer you need to build a physical layer which gracefully recovers from the likely event of a failed HDD.
Scalability
As a Database system grows in data volume, traffic volume, or complexity, there must be a method to handle the growth. For example, when we increase a load parameter and keep the system resources (CPU, memory, network bandwidth, etc.) unchanged, what happens to our Database performance, both within the Database and on the hosted hardware? Is performance degraded? Are there memory issues, or synchronisation problems? When we increase a load parameter what needs to happen to the Database and underlying physical or virtualised hardware to keep performance unchanged?
Some systems are elastic, meaning that they can automatically add computing resources when they detect a load increase, whereas other systems are scaled manually (a human analyzes the capacity and decides to add more machines to the system). An elastic system can be useful if load is highly unpredictable, but manually scaled systems are simpler and may have fewer operational surprises (see “Rebalancing Partitions”). While distributing stateless services across multiple machines is fairly straightforward, taking stateful data systems from a single node to a distributed setup can introduce a lot of additional complexity. For this reason, common wisdom until recently was to keep your database on a single node (scale up) until scaling cost or high-availability requirements forced you to make it distributed.
Maintainability
Systems are quite useless if not maintained. There is no magic ‘random chance’ of ever-performing systems ‘mutating’ over time. The opposite holds true. Over time, many different people will work on the system including engineering and operations, both maintaining current behaviour and designing the system to new use cases, and they should all be able to work on it productively. This means that the system has to be documented, modelled, understood and all schemas, relationships and dependencies mapped.
Operability
Make it easy for operations teams to keep the system running smoothly. With documentation, a simple design is best. Make it easy for new engineers to understand the system, by removing as much complexity as possible from the system. This makes it easier for engineers to make changes to the system in the future, adapting it for unanticipated use cases as requirements change. This is also known as extensibility, modifiability, or plasticity.
You must setup detailed and clear monitoring including performance metrics and error rates (sometimes called telemetry). Nagios, Splunk and other tools should be used. Monitoring can show us early warning signals and allow us to check whether any assumptions or constraints are being violated. When a problem occurs, metrics can be invaluable in diagnosing the issues.
==END