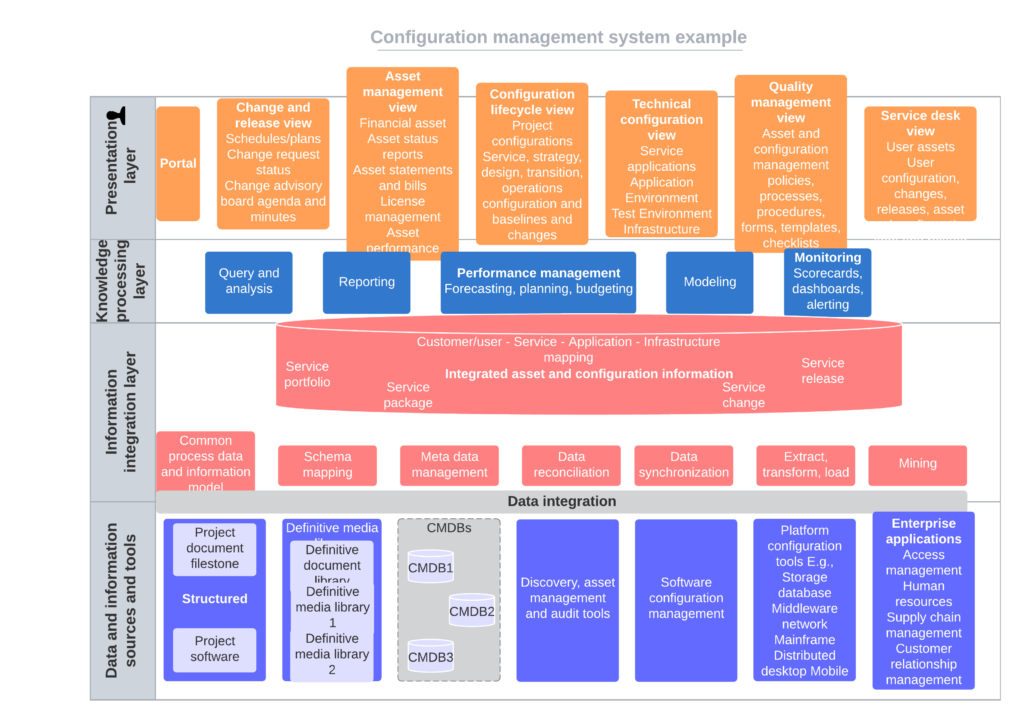
Most firms have issues with understanding their IT assets across environments. Many have more than 1 database of asset and configuration information; quite a few customise the configuration management database and make it difficult to interoperate with other systems, and update. The CMDB is an important tool to understand the current estate and create a roadmap to Cloud migration or ‘transformation’. A CMDB should be a single platform source of truth for the IT estate.
Configuration Management Database Definition
A configuration management database (CMDB) is a data repository that stores information cataloguing all hardware and software assets in the IT environment. This critical component of the ITIL framework allows for efficient oversight and management of organizational assets, known as configuration items (CI), and delivers greater insight into how they relate to one other across the company.
Assets logged in a CMDB include products, facilities, software, systems, and even key stakeholders in a process. As a centralized log of all the business’ assets, a CMDB can assist in making important business decisions and in running more efficient ITSM processes by providing an organized, updated catalogue of asset configurations and relationships. A CMDB can help organizations identify and resolve problems, respond more quickly to incidents, and improve budget forecasting, decision-making, and the deployment of network components.
Configuration item types
A configuration item type (or CI type) is an ITIL term that describes all the data of the elements or items an enterprise wants to store within the database. At the most basic level, all networks, software, hardware, and storage CI types are stored and tracked in a CMDB; as a company grows, it may choose to add more CI types to the CMDB. These may include people, markets, products, and third-party partners and vendors. The more assets that are tracked, the more information and insight organizations can have for knowledge management purposes.
The data included in a CMDB is important, and the goal is for it to be as accurate as possible. To ensure the highest accuracy, all owners and stakeholders for a CI should be involved in reviewing the data to ensure that it is accurate and consistent when added to the CMDB. Keeping the CMDB updated is difficult because of the overwhelming number of assets it might track; as CIs are introduced, updated, reconfigured, retired, or merged with other assets, all of that data needs to be updated and tracked in the CMDB as well.
Common CIs
The most common CI types include:
- Hardware
- Software
- Applications
- Communications and networks
- Devices
- Services
- Location
- Documentation
- People (including staff and contractors)
Common tracked asset relations include:
- Incidents
- Issues
- Deployments
- Changes
- Updates and upgrades
- Configurations
- User control access
CMDBs and asset management
A CMDB is different from an IT asset management system or ITAM. An ITAM data store focuses more on the lifecycle of individual assets and pertinent data such version, year, vendor, contract policies, pricing and upgrades. A CMDB goes a step further, focusing more on managing assets and how they interact with one another in the IT infrastructure. But the two can be integrated, and a CMDB can assist with ITAM to reduce risks and gather more data on assets and related incident management. For example, if there’s an asset in an ITAM register that isn’t in the CMDB, that can be discovered in a quick automated scan, enabling IT leaders to quickly determine whether it is a rogue asset or something missing from the CMDB.
CMDB benefits and challenges
The CMDB should reduce downtime and costs, improve analysis, and help meet regulatory compliance standards. A CMDB can also keep records of service codes and billing for financial analysis and perform root cause analysis to resolve CI issues. Maintaining a CMDB, however, is not without its challenges. For example, it can be difficult to keep a CMDB accurate and up-to-date, and there’s always the chance that incorrect data could lead to misguided decision-making. It also requires a lot of staff time and resources to collect and maintain data in a CMDB. With so many assets to include, a CMDB can also be overwhelming to manage.
CMDB for compliance and metrics
CMDBs can also be useful for analysis of dependencies, software and hardware builds, inventory, incident management, impact analysis, root cause analysis, and change management. The typical CMDB involves a dashboard that can quickly deliver insights into CI (Configuration Items) metrics and analytics. Dashboards enable businesses to track how CIs are performing, especially after changes are made to the asset. It can also give a better picture of the amount of money and resources that go into the creation and maintenance of all the services in the organization.
CMDBs are also useful for maintaining compliance measures for auditing given that it logs all the changes made to a CI over time and any problems or issues. Assets can typically be input manually, through digital integrations and automated tools that scan the IP addresses to collect data on software and hardware. Through a CMDB, organizations can also manage access controls, IT service mapping, and the creation of federated datasets.
Schematic representations of the CMDB
Database schemas are visual representations of data that is stored in the organization’s database. There are two common database schemas for a CMDB: a relational data model and a semantic data model.
The relational data model is based on first-order predicate logic presented in an ordered sequence that can’t be modified while the program is running, also referred to as a “tuple.” In this model, CIs are connected by unique “keys” that link the assets together and provide specific answers to user queries via retrieval procedures.
The semantic data model relies more on the resource description framework, which is a metadata data model that uses a subject-predicate-object approach, often referred to as “triples.” This model maps the relationship between several assets through the use of relationship descriptors to offer better context into the relationship between assets.
Edited, Link to original