A key objective of a cloud management system, indeed of a Cloud platform in general, is to provide the customer a portal (usually web-based) to order cloud services, track billing, auditing of Cloud resources and API usage; and automatically provision services that they order. Sophisticated cloud management systems will not only provision services based on customer orders, but also can automatically update network and datacenter monitoring and management systems whenever a new VM or software application is created.
REDUNDANCY, AVAILABILITY, CONTINUITY, AND DISASTER RECOVERY
Modern datacenters and particularly cloud services require careful consideration and flexible options for redundancy, high availability, continuity of operations, and disaster recovery, including:
Redundancy
Redundancy is achieved through a combination of hardware and/or software with the goal of ensuring continuous operation even after a failure. Should the primary component fail for any reason, the secondary systems are already online and take over seamlessly.
Examples of redundancy are multiple power and cooling modules within a server, a RAID-enabled disk system, or a secondary network switch running in standby mode to take over if the primary network switch fails.
High availability
High availability (HA) is the concept of maximizing system uptime to achieve as close to 100% availability as possible. HA is often measured by how much time the system is online versus unscheduled outages—usually shown as a percentage of uptime over a period of time. Goals for cloud providers and customers consuming cloud services are often in the range of 99.95% uptime per year. The SLA will determine what the cloud provider is guaranteeing and what outages, such as routine maintenance, fall out- side of the uptime calculation.
If you expect 99.99% uptime, this means four minutes of maximum outage per month. Many VMs, OSs, and applications will take longer than this just to boot up so HA configurations are necessary to achieve higher uptime requirements.
You can achieve the highest possible availability through various networking, application, and redundant server techniques, such as the following:
- Secondary systems (e.g., physical or VMs) running in parallel to the primary systems—these redundant servers are fully booted and running all applications—ready to assume the role of the primary server if it were to fail. The failover from primary to secondary is instantaneous, and causes no outages nor does it have an impact on the customer.
- Using network load balancers in front of servers or applications. The load balancer will send users or traffic to multiple servers to maximize performance by splitting the workload across all available servers. The servers that are fed by the load balancer might be a series of frontend web or application servers. More advanced load-balancing systems can even sense slow performance of their downstream servers and rebalance traffic to other servers to maintain a performance SLA (not just an availability SLA).
- Deploy clustered servers that both share storage and applications, but can take over for one another if one fails. These servers are aware of each other’s status, often sending a heartbeat or “are you OK?” traffic to each other to ensure everything is online.
- Applications specifically designed for the cloud normally have resiliency built in. This means that the applications are deployed using multiple replicas or instances across multiple servers or VMs; the application continues to service end users even if one or more servers fail.
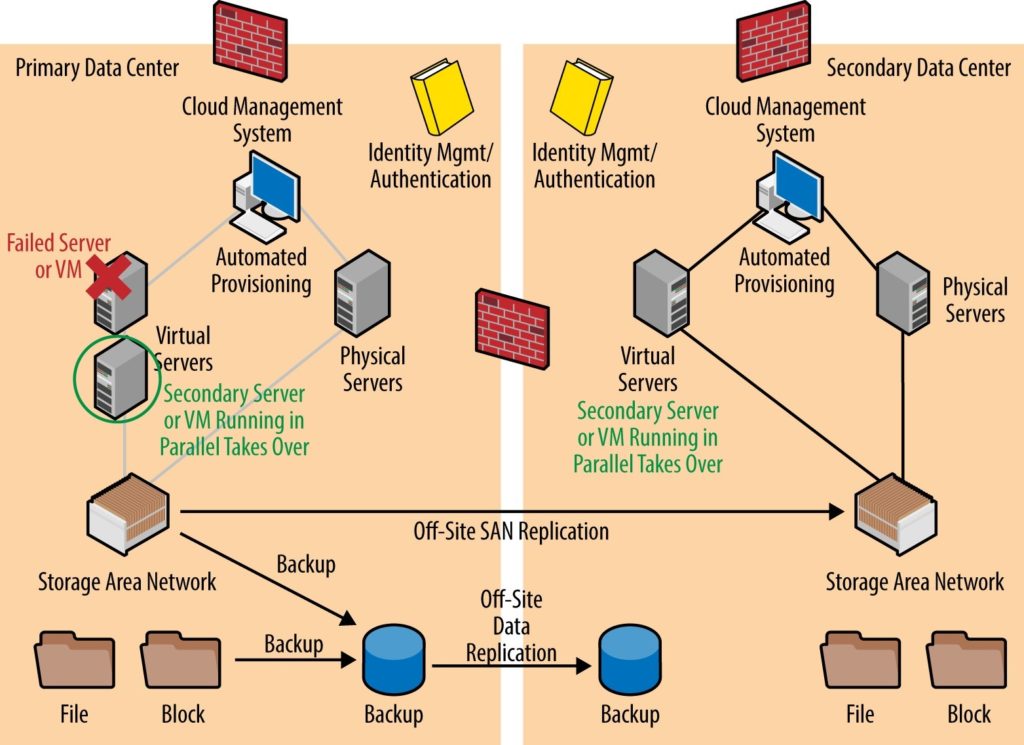
The below figure is an example of an HA scenario. In this example, a VM has failed and secondary VMs are running and ready to immediately take over operations. This configuration has two redundant servers—one in the same datacenter on a separate server blade and another in the secondary datacenter. Failing-over to a server within the same datacenter is ideal and the least likely to impact customers. The redundant servers in the secondary datacenter can take over primary operations should multiple servers or the entire primary datacenter experience an outage.