The vast majority of enterprises still employ manual processes, silos, and have a lack of documentation and resources who understand automation. Many IT personnel at these firms will read about NetFlix, Google, or Amazon – all new firms who did not have deep and complex legacy systems – and decide that they too should have a completely automated end to end infrastructure and application-code deployment process; even though their business models have nothing in common with these and other well-known practitioners of ‘agile-computing’.
Most VLEs are 3-5 years away from having an automated and consistent process of code and application delivery and deployment. Almost every VLE who wishes to automate their infrastructure views it as 3-6 month project. Thus, frustration and anger issue forth, when the current broken-manual system is not magically transformed into ‘devops’ within 6 months. The ‘Agile’ group responsible for this impossible deadline is declared to have ‘failed’, and the Waterfall totalitarians re-enter the scene, with a centralized dictatorship, to ‘make sure we get this project finished’. Years later not much is accomplished.
Some issues with end-to-end automation including infrastructure as code:
- Legacy Systems: VLEs have patched together many disparate systems over time; using a wide variety of products and components. Replacing these, or migrating applications using such underlying legacy platforms can be difficult and could involve rewriting of code, or platform-level replacements.
- Methodology: Most firms do no understand ‘DevOps’, Agile or non-Waterfall thinking. If you try to use Waterfall to command-and-control infrastructure and application improvements, you will fail. If you try to impose Waterfall on a future system of ‘automated infrastructure deployment’, you might also want to mix diesel fuel with your coffee in the morning.
- Culture and Silos: Most VLEs still operate in ‘chunks’ and silos. It is not uncommon for IT to be split up into: Application Development, Application Support, Infrastructure Operations, Security, Networking, Database SMEs, Technical Leads, Architecture, IT help desks, BAU etc. Trying to get just IT to work together on a large project, within a silo-culture is a frustrating business.
- Target Models: Most VLEs will have difficulty deciding on which platform the improved infrastructure should reside. This is due to many factors inside the firm, a key one being a lack of target model understanding; and differing views internally as to what the target platform should offer in functionality, security, and pricing.
- No Documentation: Very few VLEs understand their legacy platforms. Most do no want to spend the time and money doing a discovery of the same. Yet if the low level details of mapping relationships, dependencies, parameters being passed, data formats, data models, data schemas, service functions, interfaces etc are not understood there is nothing you can do to remediate, migrate or improve what you have. No documentation is rife within VLEs and is a major barrier to automation.
- Financial Model: Most budgeting cycles are based on Waterfall practices, and are not broken into discrete bits of innovation including Proofs of Concepts. Business case justification is manual, based on silos, approvals and long-lead times. The financial process, by itself, can kill automation.

Some steps to move from Legacy into an automated model over time.
- Understand and document your data layer and all dependencies, transactions, parameters, formats, ETLs, loading, record sizes, queries and observe impediments, possible remediation and automation. Copy your production environment and work on creating an automated Data Layer (automated loading, HA, Failover, Clustering, improved security etc.), when doing this analysis. Test ideas away from Production to make sure there is no impact on running systems.
- Map the improved data layer process back to the application-dev process. Perform the same analysis, and come up with a plan for the automation of code deploying including embedding testing of code and systems integration.
- Choose a Target Operating Model for both code and the data flows and map out how to get the improved ‘Current Estate’ migrated over the to expected ‘Future State’ based on what you have. If you don’t know your Current Estate and what the systems are trying to do; you cannot choose your Future TOM.
- Resource, train and have SMEs who understand the TOM and who will be responsible per technology area, for the migration to the improved Future State. Decide what to do in house vs outsourcing.
- Take one application and related dependencies and move that over to the TOM. Begin the long process of turning manual development, delivery and support into an integrated ‘devops’ and automation pipeline. Once this application has gone through the ‘transformation’ process, rank all other applications for migration based on key criteria specific to the firm including business importance, readiness for change, end user impact, dependency impact and risk. Each application dependency must be mapped out before hand.
- In the TOM you must automate logging, reporting, monitoring, even patching if possible.
- Start building a TOM pattern book to standardize deployments into the TOM. This should be held by the Enterprise Architecture group and used across projects.
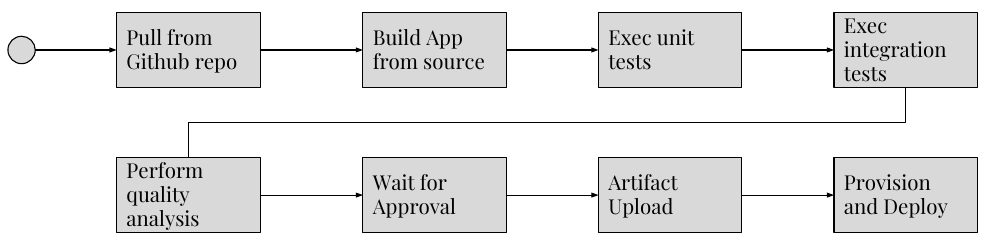
Application level DevOps basics when considering automation are below. AWS as an example:
- Start with the analysis outline above
- Move the code into AWS Code Commit, or SVN, or Github; and have a branching and trunk strategy for code deployments
- Introduce Jenkins, code-pipeline, code-deploy, Chef, or similar automation to take centralized code packages, deploy them and build. At the back-end have automation which deploys the packages onto existing, or newly created nodes based on patterns (resources needed, RAM, CPU, storage etc)
- Incorporate a quality control process via unit tests and static code analysis before
- Choose a deployment model; idempotent which is node configuration to a preferred state; or immutable infrastructure in which the servers and nodes are built, then torn down in a blue-green deployment. Both models will use slightly different CI-CD processes and tools.
- Security based on roles and permissions, needs to be built, key management should be vaulted, obviously network, subnet and instance security enforced and audited.
- Roll out every new update to the infrastructure via code by updating the idempotent or immutable stacks. Avoid making one-off changes
- Over time automate testing.
- Ensure Cloud Watch, Cloud Trail, Trusted Advisor, application monitoring (Nagios) is turned on and logs are sent to a centralized view.
- Make your changes auditable and make logging
- Define common standards across your organization and continuously optimize. The easiest way to do this is to have an Agile-Transformation COE which will have standards around proper-Agile, tools, processes, principles and security, and can help educate project teams on the same.
- Use your pattern book to deploy into the TOM.
- Security SME audits should be constant and security updates and upgrades should be done by dedicated personnel and documented.
- Document the infrastructure and keep it updated.
==END